Introducción
Esta es la continuación de mi post anterior , en donde describo el paso a paso para construir una aplicación con tres microservicios corriendo en local con Docker Compose. En este artículo, documento el proceso para desplegar la misma aplicación en la nube de AWS utilizando servicios administrados para contenedores, como Amazon ECS Fargate y Amazon ECR.
Motivadores
En mi día a día dirigiendo proyectos de tecnología, me he dado cuenta de que para liderar con verdadero impacto no basta con gestionar tiempos y presupuestos; es fundamental entender la complejidad real de lo que el equipo de ingeniería construye. Decidí ponerme en modo “hands-on” con este laboratorio por tres razones clave:
- Liderar con criterio y autoridad técnica: Quiero experimentar en carne propia los retos del despliegue en la nube para validar estimaciones, entender los “bloqueos” del equipo y asegurar que las conversaciones técnicas sean transparentes y fundamentadas.
- Consolidar un liderazgo de ingeniería real: Creo firmemente que un buen líder tecnológico debe saber de qué está hablando. Este espacio es mi bitácora para demostrar que puedo conectar la estrategia con la ejecución técnica.
- Evolución profesional: Mi meta a corto y mediano plazo es transicionar y consolidarme en roles de mayor profundidad técnica, como Arquitecto de Soluciones o Especialista en Infraestructura IT. Este laboratorio es un paso firme en esa dirección.
Arquitectura inicial
Para este laboratorio, nuestro punto de partida es el estado final del Laboratorio No. 1 de esta serie, que puedes encontrar en mi post anterior , donde construí una solución desacoplada compuesta por tres microservicios:
| Microservicio | Stack Tecnológico | Puerto Local | Endpoint / Función |
|---|---|---|---|
| frontend | HTML / CSS / JS (Nginx) | 80:80 | Interfaz de usuario web |
| usuarios | Node.js / Express | 3000:3000 | GET /users (Retorna lista de usuarios) |
| productos | Node.js / Express | 3001:3001 | GET /products (Retorna lista de productos) |
En este punto, los tres contenedores se levantan localmente con un solo comando: docker compose up.
Dado que el frontend es una SPA (Single Page Application) que se ejecuta directamente en el navegador del cliente, la comunicación hacia las APIs de backend se realiza apuntando directamente a http://localhost:3000 y http://localhost:3001.
Objetivo del Laboratorio
El objetivo en este laboratorio No. 2 es desplegar la solución local en la nube de AWS utilizando Amazon Elastic Container Service (ECS) en su modo Fargate, en donde no provisionamos instancias EC2; en su lugar AWS se encarga del cómputo subyacente, eliminando la necesidad de aprovisionar y gestionar servidores.
En este paso, tanto el frontend como las APIs de backend serán públicos, y se llaman directamente mediante las IPs propias de cada contenedor.
Si bien es cierto esta no es una arquitectura “production ready” , me permite poder entender el proceso para el despliegue de arquitectura basadas en contenedores utilizando los servicios de AWS y es un buen punto de partida para agregar más elementos de complejidad, que permitan tener escalabilidad, alta disponibilidad, y seguridad.
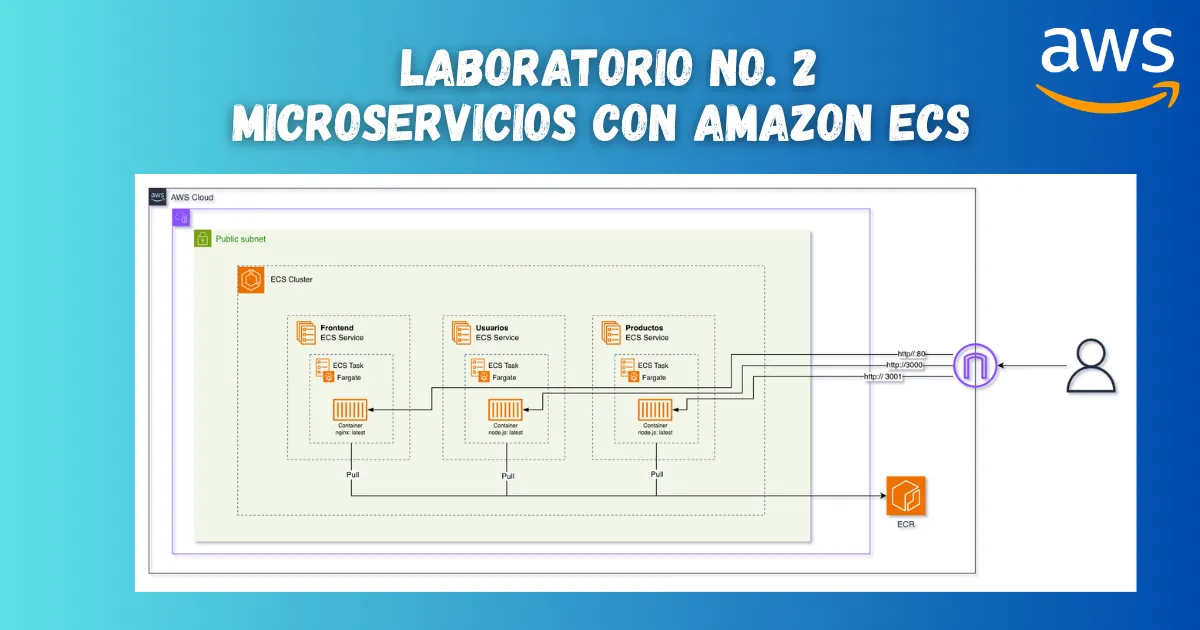
Arquitectura Objetivo
Para este ejercicio, obtendremos una arquitectura desacoplada y directa. Desplegaremos los tres microservicios como Servicios independientes en Amazon ECS bajo la modalidad Fargate, alojados dentro de una subred pública en la VPC predeterminada.
En este diseño, cada Task recibe su propia dirección IP pública, lo que permite al navegador del usuario interactuar directamente con cada componente de la siguiente manera:
- Frontend (Puerto 80): Servidor Nginx que entrega los recursos estáticos al cliente.
- Servicio de Usuarios (Puerto 3000): API en Node.js que responde a las peticiones de
GET /users. - Servicio de Productos (Puerto 3001): API en Node.js que responde a las peticiones de
GET /products.
Diagrama de Arquitectura
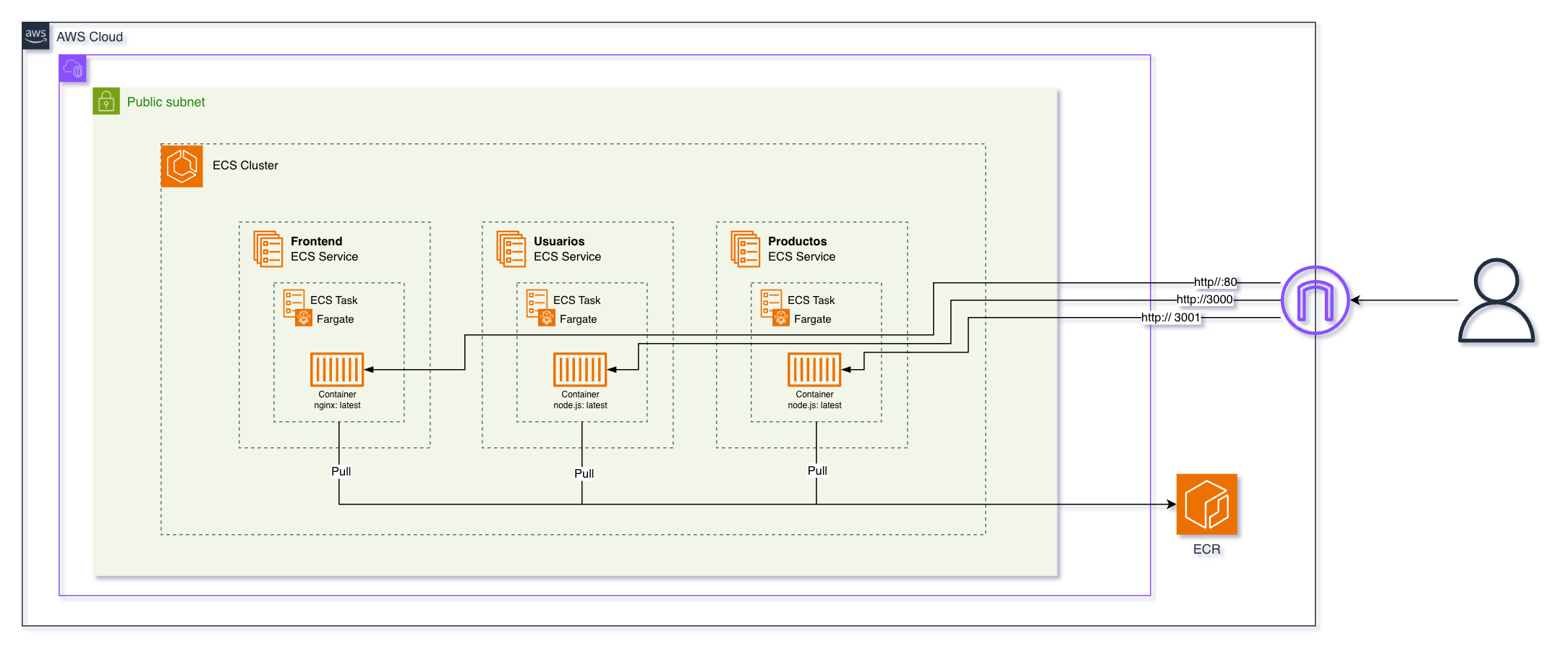
Como se observa en el diagrama, los tres contenedores mapean sus puertos nativos hacia el exterior y dependen de Amazon ECR para el aprovisionamiento de sus imágenes (nginx:latest y node.js:latest) durante el despliegue del servicio.
⚠️ Nota de Arquitectura (Disclaimer): Es evidente que esta no es una arquitectura apta para producción (production-ready). Exponer las APIs de backend directamente a internet y depender de IPs efímeras (que cambian por completo en cada redespliegue) representa un riesgo de seguridad y estabilidad operacional.
Sin embargo, este diseño simplificado es un paso pedagógico deliberado. Me permitió aislar el comportamiento nativo de Fargate, entender el ciclo de vida de las Tasks y dominar la gestión de imágenes en ECR antes de introducir la capa de abstracción de un Balanceador de Carga (ALB) en el próximo paso.
Guía Paso a Paso
Si deseas replicar este laboratorio en tu propio entorno y experimentar el despliegue por ti mismo, a continuación encontrarás la guía detallada paso a paso.
Prerrequisitos y punto de partida
Antes de ejecutar el primer comando, asegúrate de contar con lo siguiente:
- Herramientas locales: Tener instalados Docker Desktop y la interfaz de línea de comandos de AWS (AWS CLI).
- Cuenta de AWS: Acceso a una cuenta con permisos para gestionar ECR, ECS e IAM.
Para situarte exactamente en el punto inicial para este ejercicio (el estado final del Laboratorio No. 1), abre tu terminal y ejecuta los siguientes comandos para clonar el repositorio y moverte al commit donde nos quedamos en el articulo anterior :
| |
Con el entorno preparado y el código base listo, ¡comencemos!
Paso 1: Ajustar el código
Antes de subir a AWS hay dos cambios necesarios en el código.
1.1 Agregar health check a los backends
Fargate necesita saber si un Task está viva. Para eso hace peticiones HTTP a un endpoint y espera un 200 OK. Sin esto, el Task puede quedar en un loop de reinicios.
Agregamos el siguiente código en servicio-usuarios/index.js y servicio-productos/index.js, antes del app.listen. El contenido de la respuesta no importa — solo el código 200.
| |
Nota: Agregar el endpoint de health check en el código es solo el primer paso — Fargate también necesita ser configurado explícitamente para utilizarlo. Por ahora dejamos esa configuración pendiente y la completaremos en el próximo laboratorio.
1.2 Centralizar las URLs en el frontend
En el código actual del frontend, las URLs de los backends están hardcodeadas así:
| |
En AWS esto no va a funcionar porque cuando el navegador vea localhost va a ir a buscar la máquina donde está el usuario, y no a los contenedores en AWS. Sin embargo para poder conocer las URLS correctas, primero necesitamos saber la IP pública de los contenedores, y eso solo lo sabremos una vez despliegue las Task en Fargate.
Cambiamos el bloque <script> del index.html para centralizar las URLs en un solo lugar y poder modificarlo cuando lo necesitemos:
| |
Y también modificamos el código en el llamado de los botones:
| |
Antes de continuar, probamos que todo siga funcionando en local
| |
Paso 2: Crear repositorios en ECR
Antes de seguir, debemos configurar donde vamos a guardar las imágenes de Docker que utilizaremos para desplegar los contenedores, esto lo hacemos con el servicio Amazon Elastic Container Registry (ECR).
Amazon ECR es el registro privado de imágenes de AWS — el equivalente a Docker Hub pero dentro de nuestra cuenta de AWS.
Buscamos el servicio de Amazon ECR en la consola y en la página inicial seleccionamos Create a repository

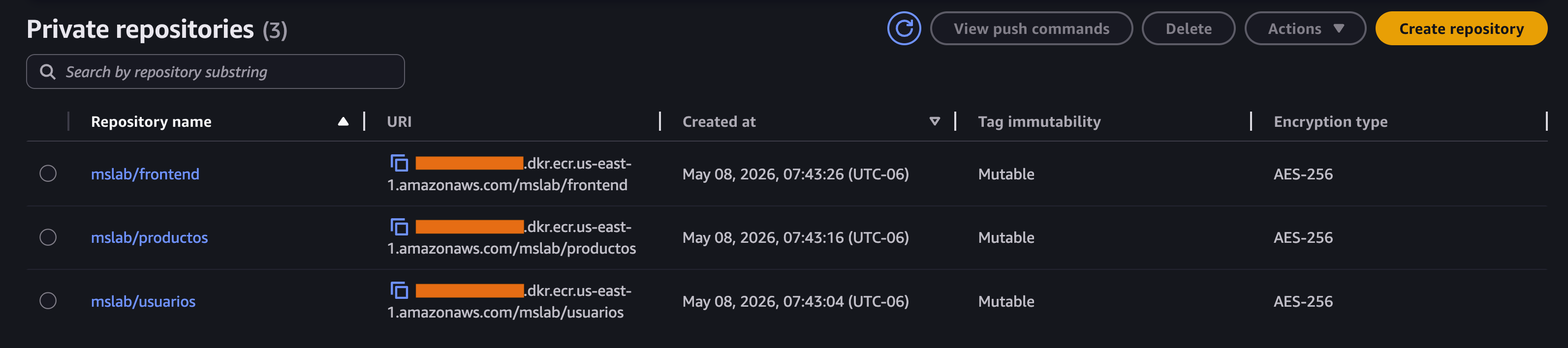
Vamos a crear tres repositorios desde la consola de ECR con estos valores:
- Nombres:
mslab/usuariosmslab/productosmslab/frontend
- Image tag settings:
Mutable - Encryption settings:
AES-256 - Valores restantes por defecto.
Así nos aparecerá en la consola luego de crear los tres repositorios, cada uno tiene una URI que utilizaremos más adelante.
Paso 3: Construir y Subir las imágenes a ECR
3.1 Autenticar Docker con Amazon ECR
Ahora que ya tenemos un “lugar” donde colocar las imágenes de nuestros contenedores en AWS, debemos subirlas a Amazon ECR; para esto la única forma es utilizar la línea de comandos de AWS CLI.
⚠️ Prerrequisito: Los comandos de este laboratorio asumen que ya tienes el AWS CLI instalado y autenticado contra una cuenta de AWS. Si aún no lo has configurado, consulta la documentación oficial de AWS o busca en este blog donde puede haber un artículo al respecto.
Primero confirmamos que tenemos Docker corriendo en nuestra computadora
| |
Con este comando obtenemos un token de autenticación temporal de ECR via AWS CLI, y lo pasamos directamente a Docker para autenticarse contra el registry privado. El token tiene una validez de 12 horas. Sustituir xxxxxxxxxxx por el número de cuenta AWS que estes utilizando y my-profile con el nombre del perfil que estemos utilizando para AWS CLI.
| |
Si todo sale bien debe responder Login Succeeded.
3.2 Build
Ahora que ya tenemos Docker en nuestra computadora “autorizado” para subir las imágenes a Amazon ECR, debemos construir nuevas imágenes de forma local y subirlas a ECR, ese proceso se llama build.
Es importante notar que en mi caso estoy en una computadora Mac con Apple Silicon (M1/M2/M3), por lo que cuando hacía el build para correr el contenedor de forma local, Docker construía las imágenes para la plataforma ARM por defecto. Sin embargo, para que dichas imágenes puedan ser ejecutadas en Fargate, estas deben construirse especificando la plataforma AMD64, de lo contrario los Task van a fallar con un error exec format error.
Este sería un ejemplo del comando para hacer el build de una de las imágenes forzando la plataforma a Linux/AMD64.
| |
3.3 Tag
Luego del build, necesitamos colocarle un alias a la imagen que acabamos de construir asociada con la URL del repositorio destino. Es como crear un acceso directo que Docker necesita para saber donde hacer push. Por ejemplo:
| |
3.4 Push
Finalmente ejecutamos el comando para hacer push de la imagen construida a ECR. Docker usa el alias que pusimos en el tag para saber a qué registro y repositorio enviarla.
| |
Esta sería la secuencia de comandos completa para hacer build, tag y push de las tres imágenes para los tres microservicios.
| |
Así deberíamos verlos en la consola de ECR una vez completada la subida.
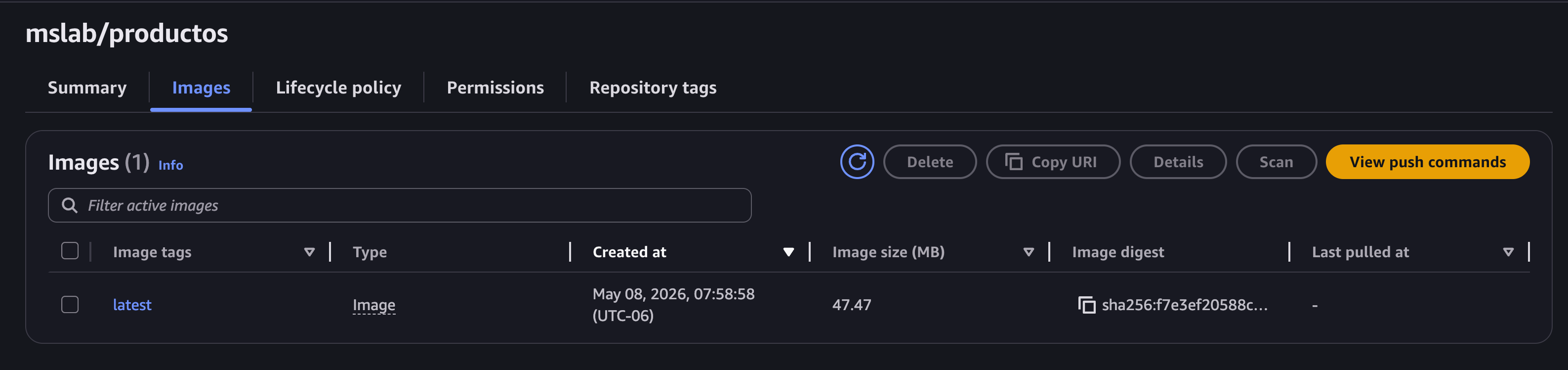
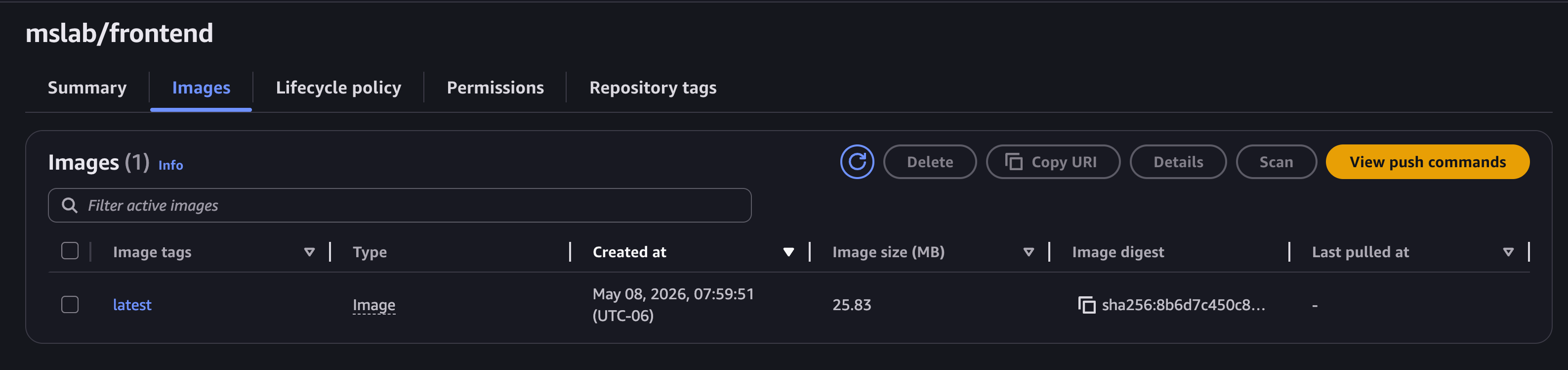
Paso 4: Crear el cluster en ECS
Un Cluster de ECS es una agrupación lógica de todos los Services de mi proyecto. Cada Service corresponde a un microservicio de la aplicación, y es responsable de mantener corriendo el número deseado de Tasks.
Cada Task se lanza a partir de una Task Definition, que es como el plano o plantilla donde se define la imagen del contenedor, los recursos de CPU/memoria y la configuración del puerto.
La jerarquía es Cluster→ Service→ Task.
En la consola de ECS, vamos a la sección de Clusters, y pinchamos en Create Cluster
Colocamos la siguiente configuración
- Cluster name:
mslab-cluster - Infrastructure:
Fargate only
El resto lo dejamos por defecto
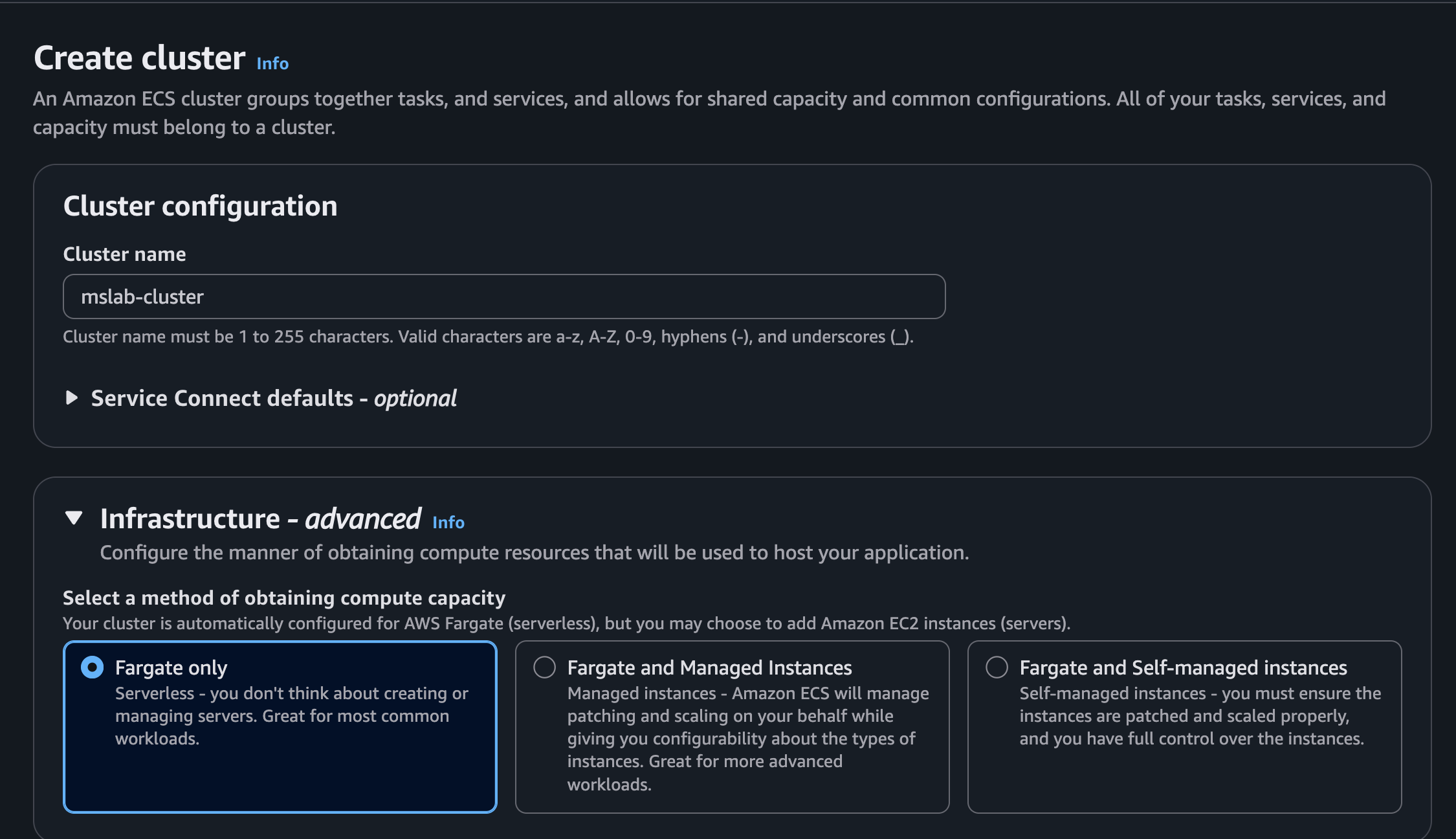
Nos debe quedar así luego de crearlo.
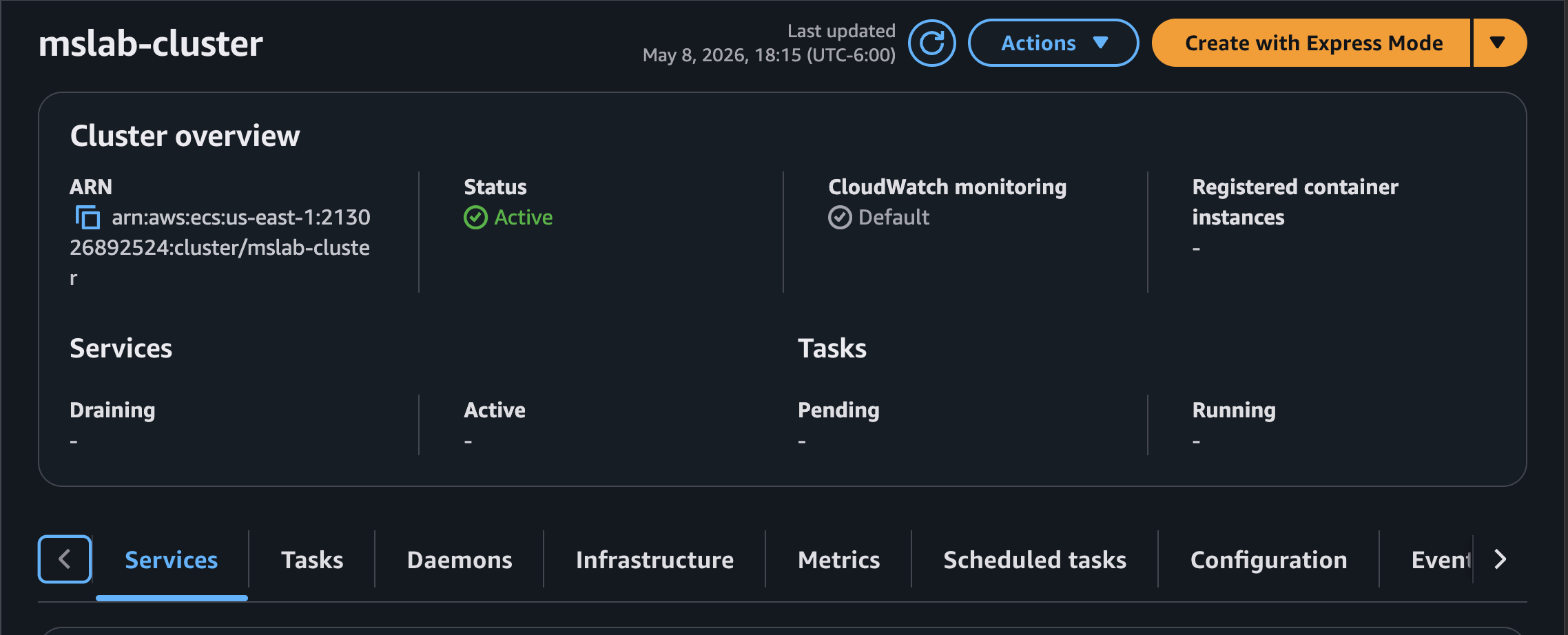
Paso 5: Crear las Task Definitions
Una Task Definition es el “plano” del contenedor — le dice a Fargate qué imagen usar, cuántos recursos asignar y qué puertos abrir. Es el equivalente a un bloque service en el docker-compose.yml.
En la consola, vamos a ECS, buscamos la sección de Task Definition y seleccionamos Create new task definition.
Creamos una Task Definition por cada microservicio con los siguientes parámetros:
Configuración base (igual para los tres):
| Campo | Valor |
|---|---|
| Launch type | AWS Fargate |
| OS/Architecture | Linux/X86_64 |
| CPU | 0.25 vCPU |
| Memory | 0.5 GB |
Container por servicio:
| Servicio | Family | Image URI | Puerto |
|---|---|---|---|
| usuarios | mslab-usuarios | ...dkr.ecr.../mslab/usuarios:latest | 3000 |
| productos | mslab-productos | ...dkr.ecr.../mslab/productos:latest | 3001 |
| frontend | mslab-frontend | ...dkr.ecr.../mslab/frontend:latest | 80 |
Quedando de la siguiente manera:
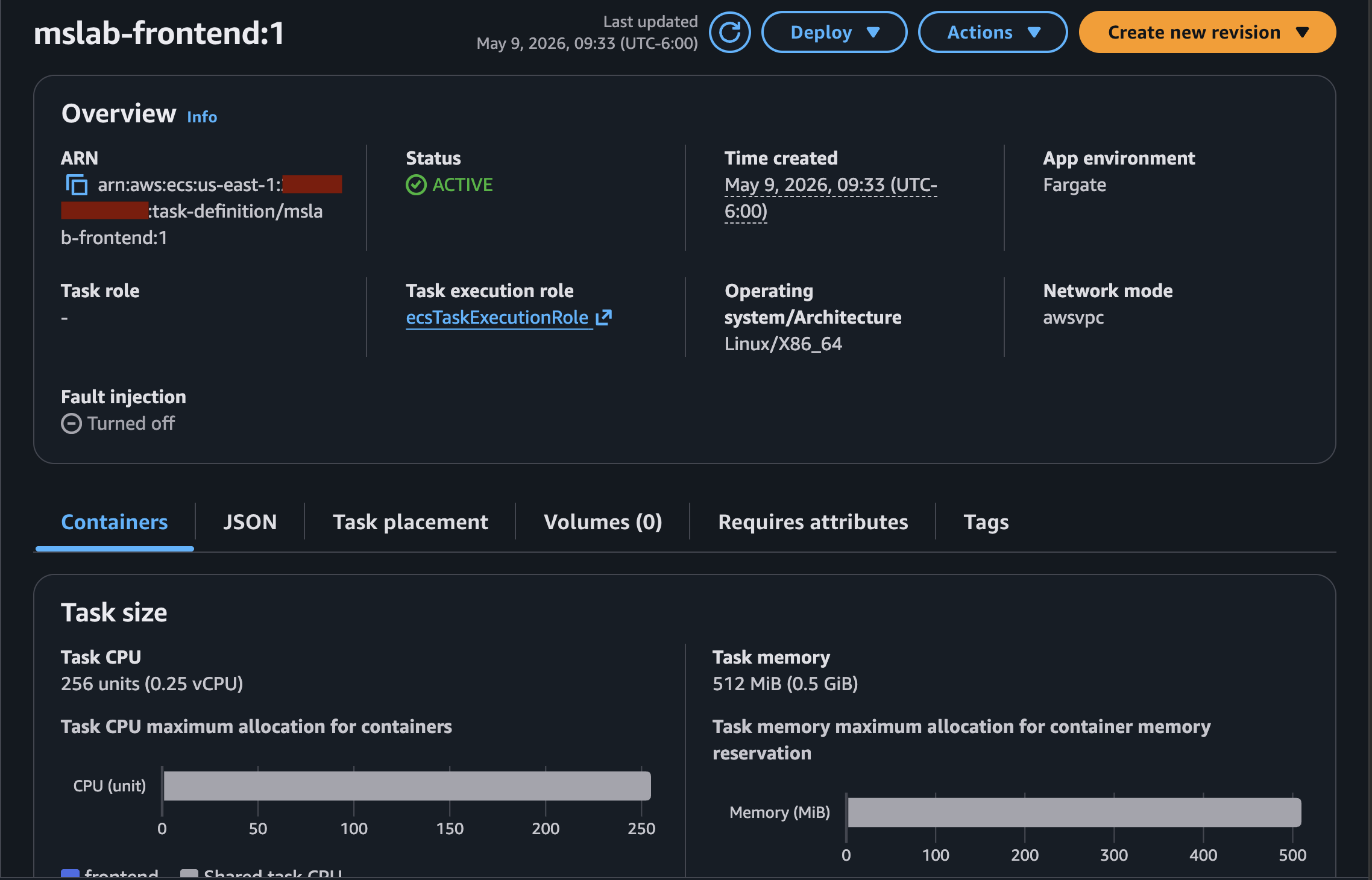
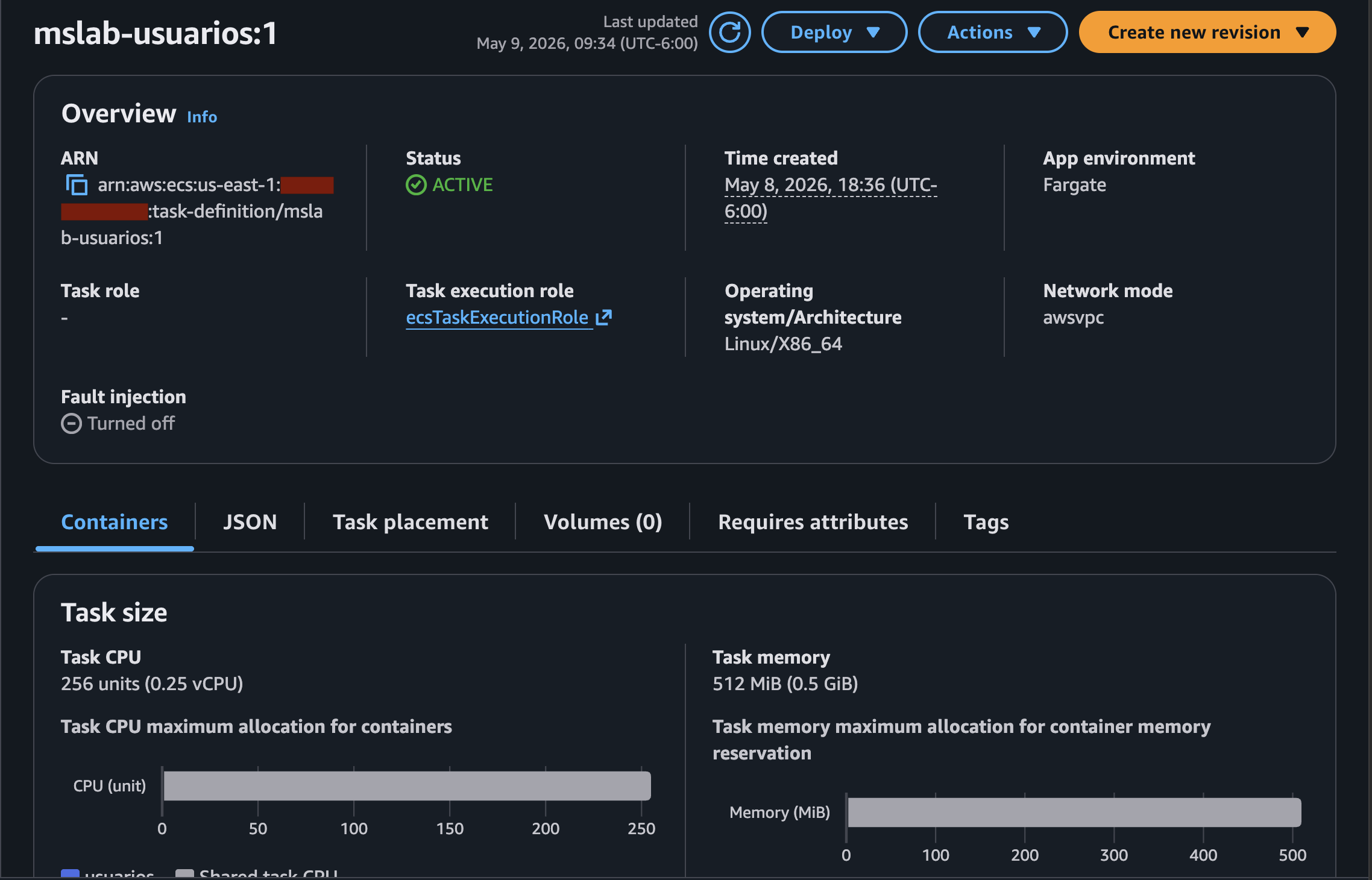
Notemos que en todos aparece un número 1 después del nombre, esto es la revisión del Task Definition
Nota: > Al seleccionar la imagen desde el navegador de ECR, asegurarse de que el Image URI quede con
:latesty no con el digest@sha256:.... Si queda con el SHA256 y luego actualizas la imagen, Fargate va a buscar un digest que ya no existe y el Task va a fallar.
Importante: Fargate necesita un IAM Role asignado a la Task Definition para poder hacer
pullde imágenes desde ECR y escribir logs en CloudWatch. Sin él, las Tasks fallan al iniciarse con un error de permisos. En este caso al hacer el proceso por medio de la consola de AWS, esta crea y asigna elecsTaskExecutionRoleautomáticamente, y es por eso que para este paso necesitamos utilizar un usuario con permisos necesarios para crear roles, sin embargo si creas las Task Definitions utilizando AWS CLI o IaC (CloudFormation, Terraform), deberás definirlo y asignarlo explícitamente.
Paso 6: Crear los Services
Los Services en Amazon ECS, como su nombre lo sugiere, son la representación lógica de cada microservicio. Cada Service se encarga de mantener una cantidad establecida de Tasks corriendo en cualquier momento; si alguna muere, este la reinicia.
La diferencia entre un Task y un Service se puede entender así:
- Task — una ejecución puntual. Si muere, no vuelve, es efímera.
- Service — mantiene N Tasks corriendo siempre. Si uno muere, lo reinicia.
Para este laboratorio cada Service mantiene solamente 1 Task, pero en un sistema de producción lo más común es tener más de una Task por Service, distribuidas en múltiples Zonas de Disponibilidad, lo cual provee tanto escalabilidad horizontal como alta disponibilidad ante fallos de infraestructura.
6.1 Servicio Usuarios
Para crear un Service, vamos a la consola de Amazon Elastic Container Service y en la sección de Cluster seleccionamos el que acabamos de crear mslab. Luego buscamos la pestaña de Services y seleccionamos Create
y configuramos estos parámetros del servicio
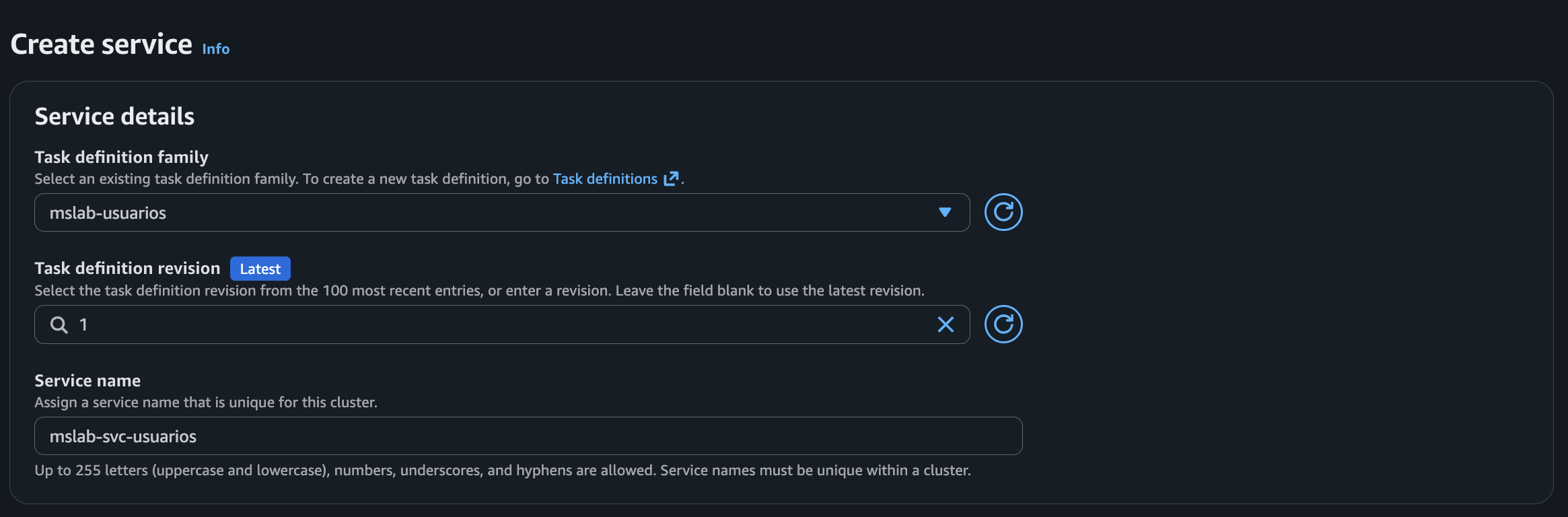
- Task definition family:
mslab-usuarios - Task definition revision:
1(solo esa existe en este momento) - Service name:
mslab-svc-usuarios
En la sección de Deployment configuration, dejamos Replica y Desired Task: solamente 1 por el momento.
En la parte de Networking configuramos estos parámetros los cuales serán comunes para el resto de servicios.
| Campo | Valor |
|---|---|
| VPC | default |
| Subnets | us-east-1a |
| Public IP | Turned on ← crítico |
| Security group | Create a new security group |
Necesitamos crear un nuevo Security Group para cada Service, en el caso de Usuarios, lo llamamos mslab-sg-usuarios, y este debe permitir el tráfico entrante en el puerto 3000 desde cualquier origen: 0.0.0.0/0.
La configuración queda de esta forma, al finalizar seleccionamos Create.
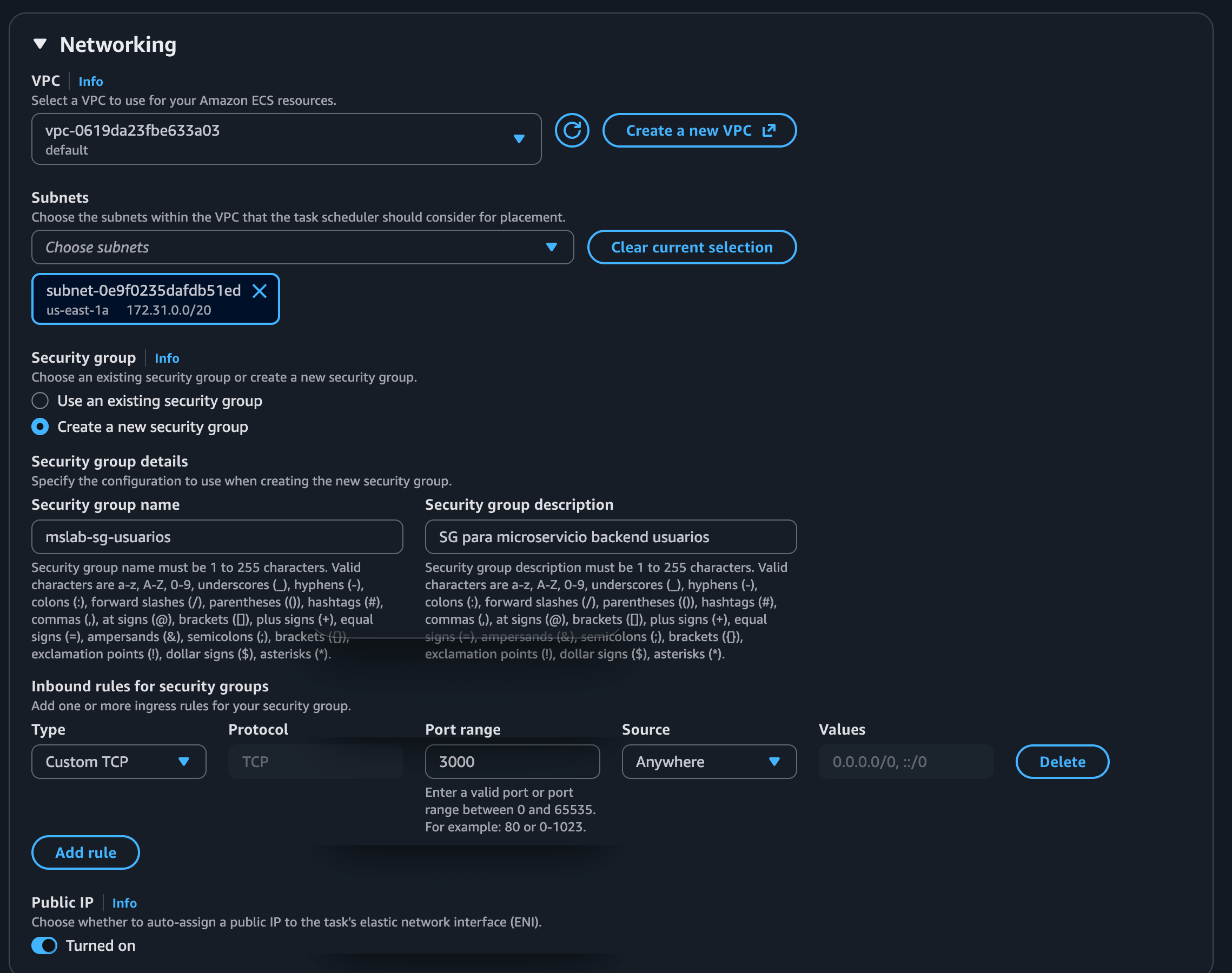
Important: > Para este laboratorio, todos los microservicios tienen IP pública para poder comunicarse entre ellos. Esta no es una práctica recomendada — en una solución de producción, los servicios de backend no se exponen directamente a internet sino que se acceden desde un único punto de entrada privado, típicamente un Application Load Balancer (ALB).
6.2 Servicio Productos
Repetimos los mismos pasos para crear un nuevo servicio con estos valores:
- Task definition family :
mslab-productos - Task definition revision: 1
- Service name:
mslab-svc-productos
Creamos el nuevo Security Group de esta forma:
| Campo | Valor |
|---|---|
| Security group name | mslab-sg-productos |
| Inbound rule tipo | Custom TCP |
| Inbound rule puerto | 3001 |
| Source | 0.0.0.0/0 |
El resto de valores son iguales que el anterior.
6.3 Servicio FrontEnd
Repetimos los pasos para el servicio de frontend.
- Task definition family:
mslab-frontend - Task definition revision: 1
- Service name:
mslab-svc-frontend
Para el Security Group:
| Campo | Valor |
|---|---|
| Security group name | mslab-sg-frontend |
| Inbound rule tipo | Custom TCP |
| Inbound rule puerto | 80 |
| Source | 0.0.0.0/0 |
El resto de valores son iguales que los anteriores.
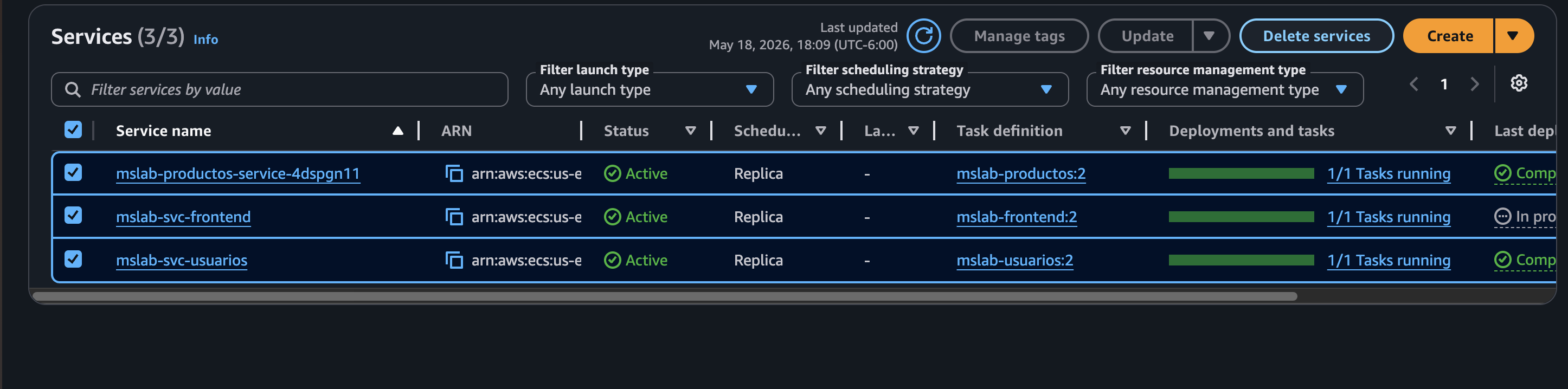
Paso 7: Verificar Services y Tasks en Running
Al finalizar la creación deberíamos ver en el Cluster los 3 Services en estado Active, así como los 3 Tasks en estado Running.
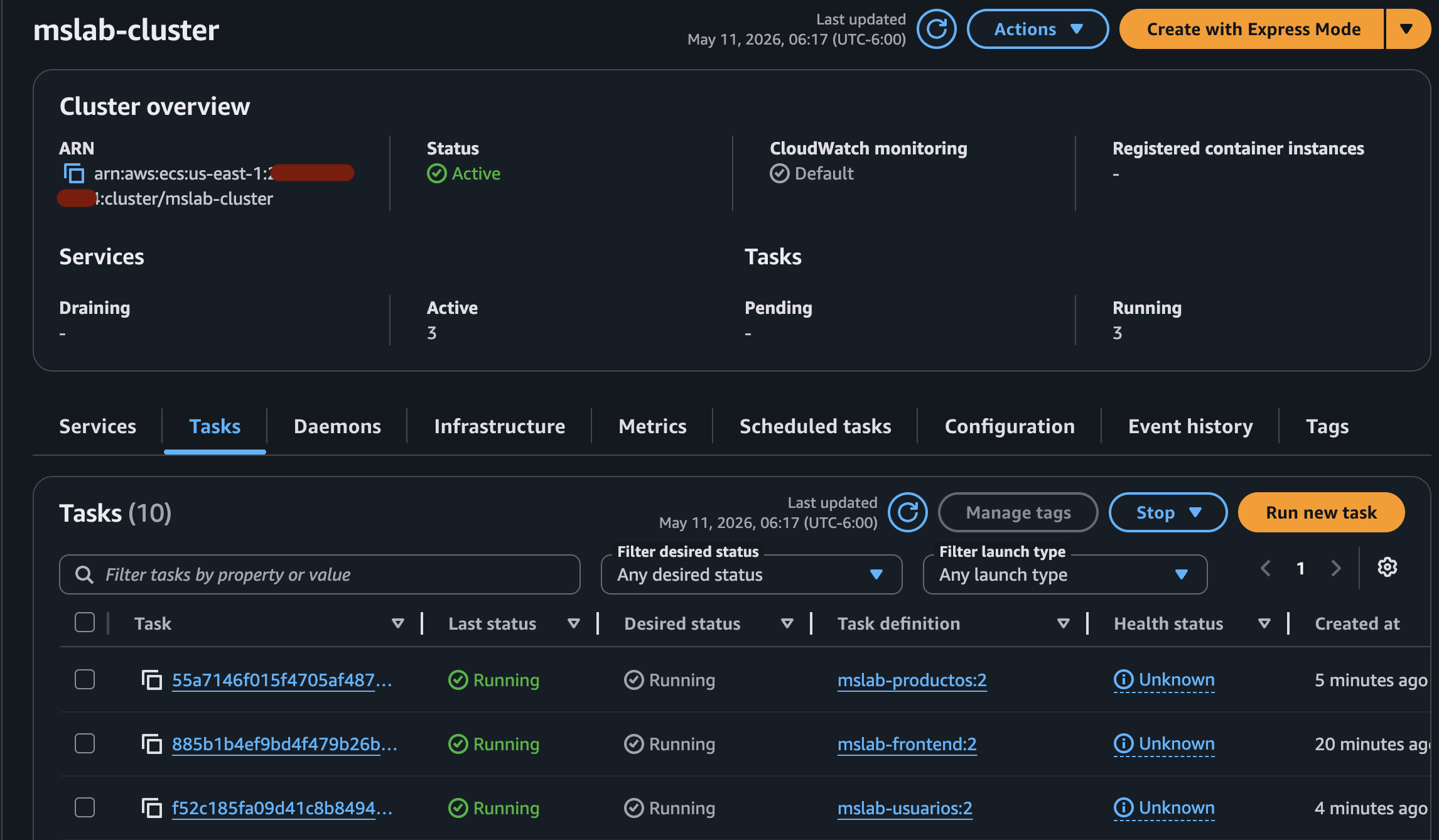
Hacemos click en alguna de las Tasks y nos abre los detalles de la misma, en donde vemos la dirección IP asignada, así como otros datos del contenedor en ejecución
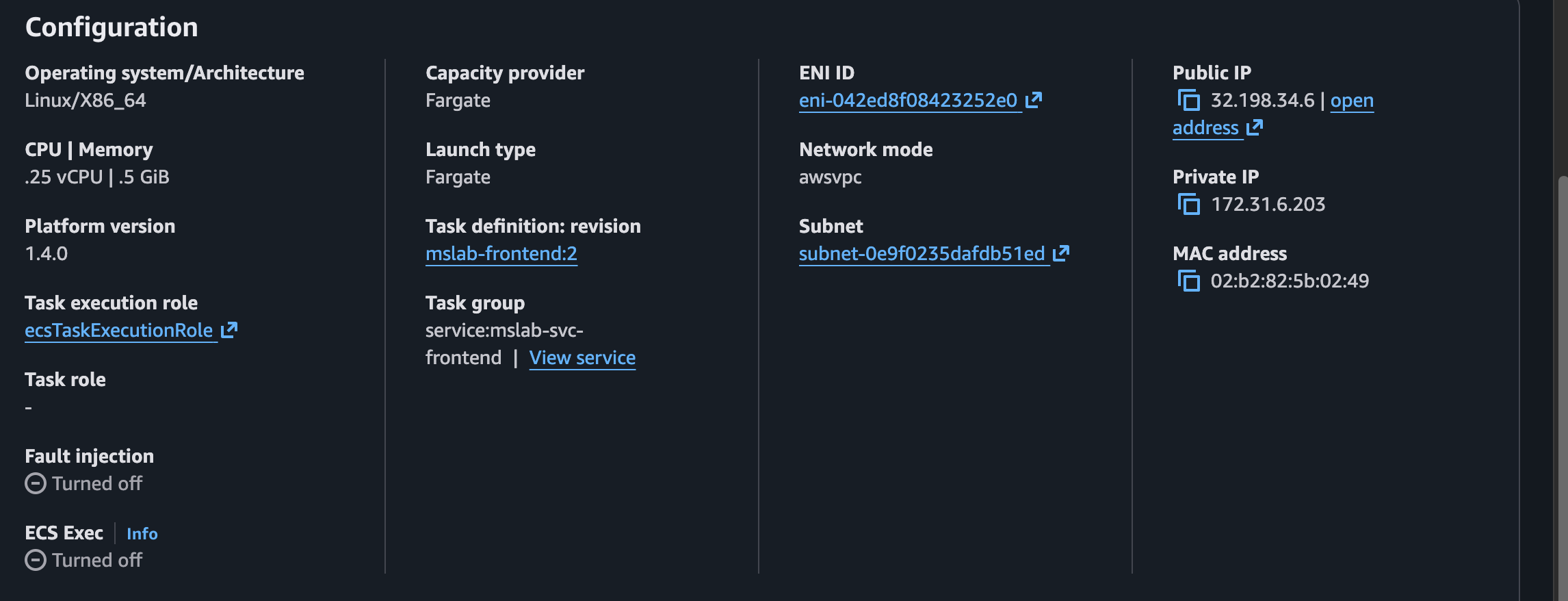
Si colocamos la IP asignada al contenedor de frontend en el navegador, nos muestra la página principal y con esto confirmamos que dicho servicio está disponible.
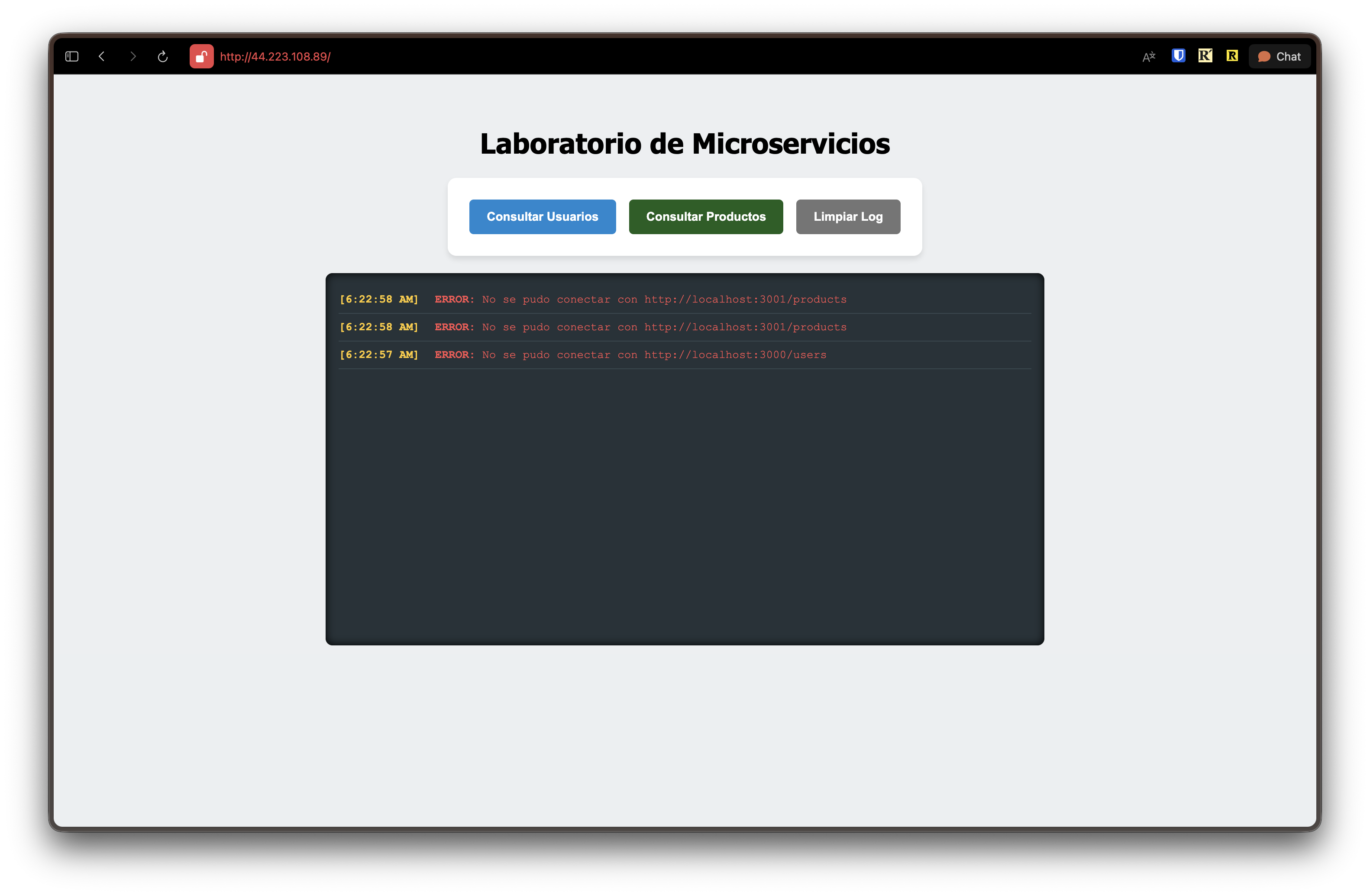
Sin embargo al hacer click en los botones para consultar las APIs de Usuarios y Productos nos genera un error, esto es porque el código aún apunta a las URLS de localhost y no a las IPs reales de los contenedores de backend.
Paso 8: Actualizar el frontend con las IPs reales del backend
Ahora que conocemos las IPs de los servicios de backend, debemos actualizar el código del frontend para que apunte a las URLs correctas, y luego repetir el ciclo completo: build → tag → push a ECR → actualizar el Service para que tome la nueva imagen.
Esta es la parte más engorrosa del laboratorio, y en un ambiente productivo es completamente inviable: cualquier redespliegue del backend — ya sea por un cambio de código o por un fallo que genere una nueva IP — obliga a repetir todo el proceso en el frontend también. Este problema desaparece cuando incorporemos un ALB, que actúa como punto de entrada estable hacia los servicios de backend independientemente de si sus IPs cambian.
Actualizamos el código del frontend con las IPs reales obtenidas en el paso anterior:
| |
Luego en la terminal reconstruimos la imagen, la taggeamos y hacemos push a ECR, para finalmente forzar un nuevo deployment en el Service de frontend:
| |
Volvemos a la consola de AWS y vamos ECS → Cluster → Services, buscamos el servicio de frontend (mslab-svc-frontend) y seleccionamos donde dice Update Service
Chequeamos donde dice Force new deployment y el resto de parámetros los dejamos como están
Al completar el despliegue del Service veremos una nueva Task la cual ya tiene la actualización del código, por ser un nuevo contenedor, tiene una nueva IP. Nos vamos al detalle de la Task y visualizamos la nueva IP asignada.
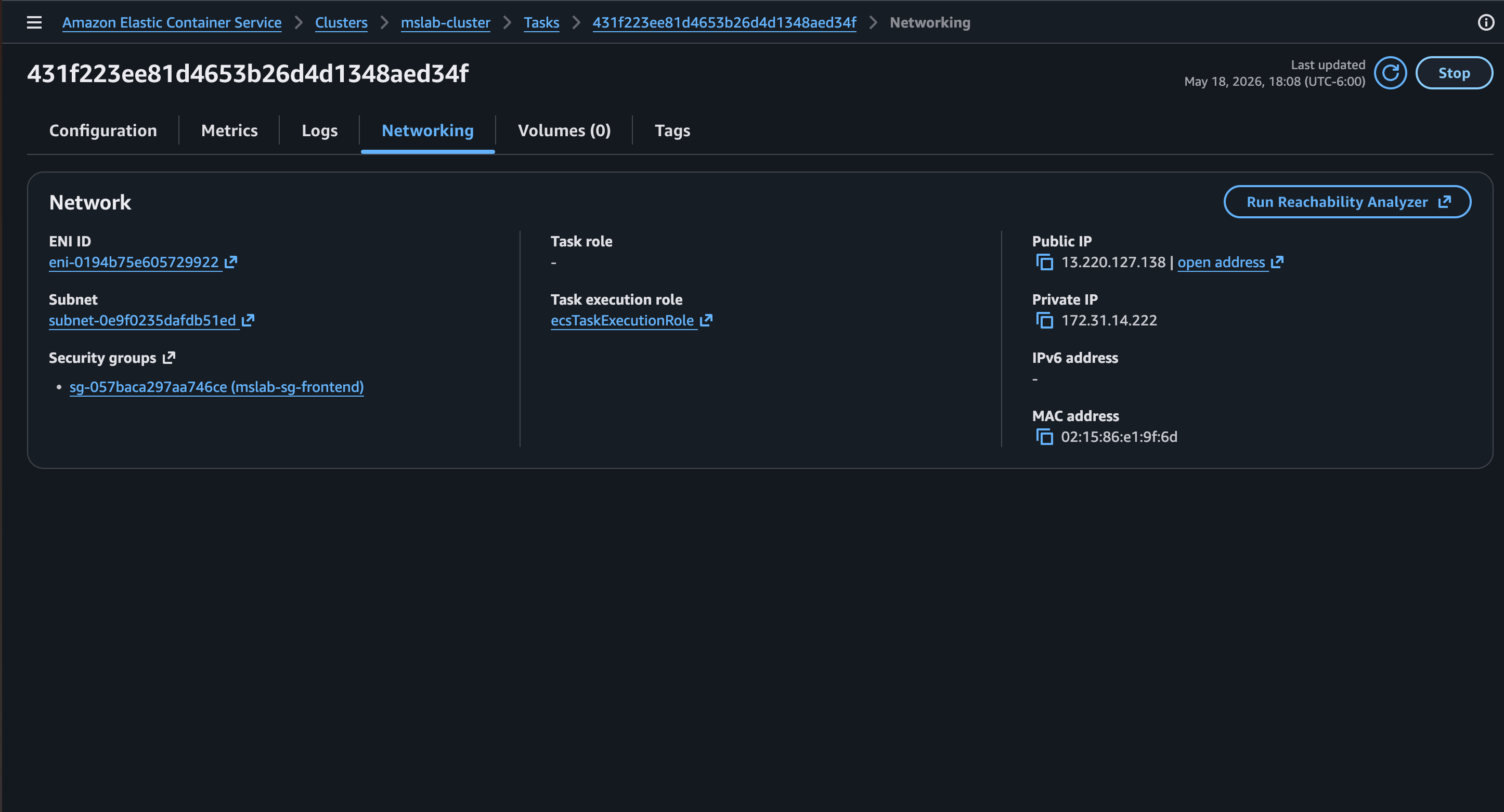
Actualizamos la URL en nuestro navegador para apuntar a la nueva IP y vemos nuevamente la página principal — pero la diferencia es que al presionar los botones de consulta Usuarios y Productos, ahora sí nos devuelve la respuesta de manera exitosa.
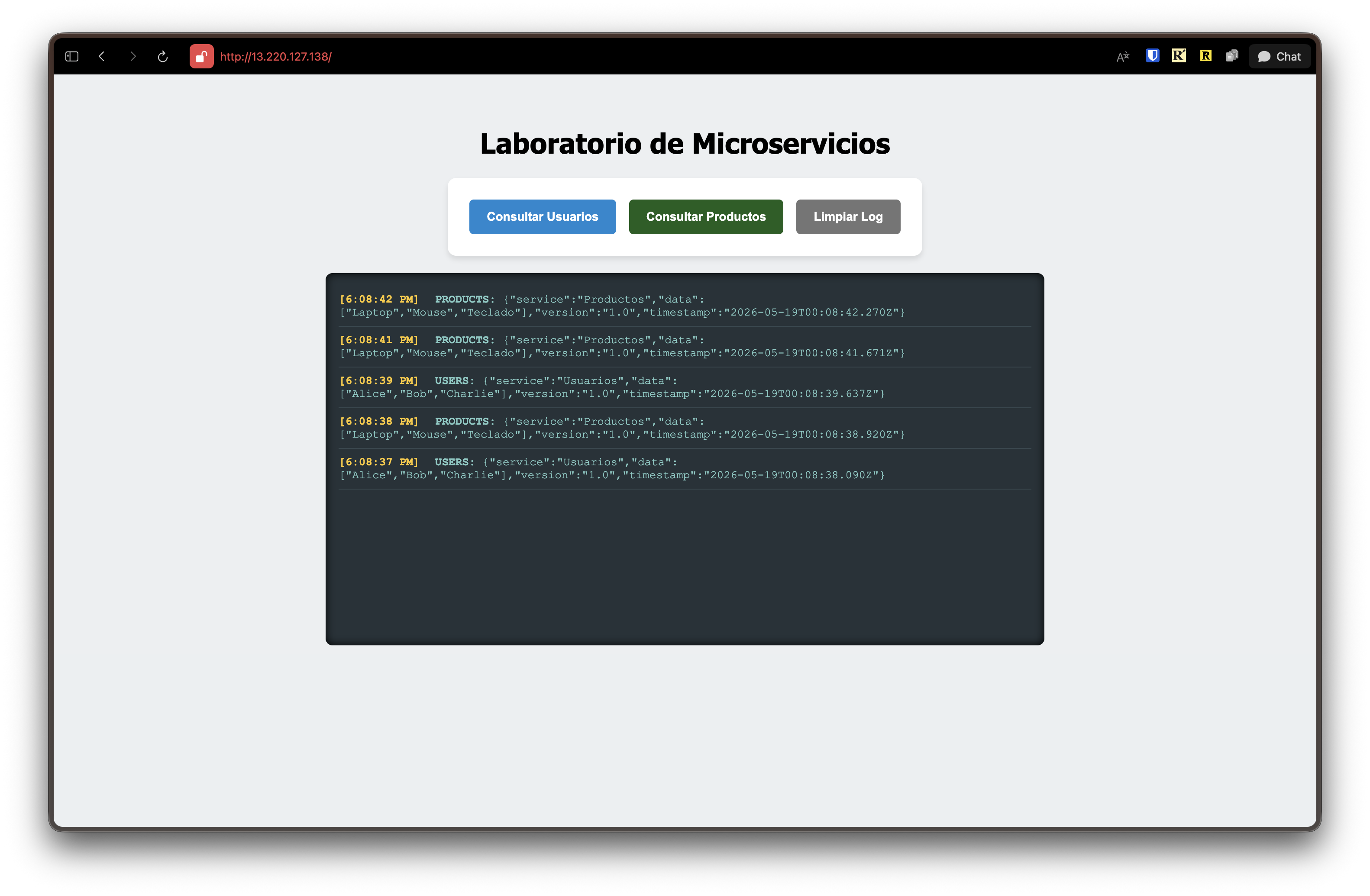
🎉🥳 Felicidades! Ésta es la prueba de fuego: todo está funcionando y confirmamos que nuestra solución está corriendo en la nube 🚀☁️
Nota técnica: En este paso las IPs de los backends quedaron hardcodeadas dentro de la imagen Docker del frontend. Esto es un anti-patrón: la configuración de entorno no debería estar embebida en la imagen, sino inyectada en tiempo de ejecución. La consecuencia práctica es que si cualquiera de los Services de backend se reinicia y obtiene una nueva IP, la imagen del frontend queda inútil y hay que repetir todo el ciclo de rebuild. La solución correcta es leer las URLs desde variables de entorno y configurarlas en la Task Definition — algo que abordaremos en el próximo laboratorio.
Paso 9: Limpieza de recursos
El último paso sería borrar únicamente los Services para no incurrir en costos de AWS. En el caso que queramos volver a desplegar la solución otra vez, únicamente necesitamos volver a crear los Services de backend, anotar las IPs, actualizarlas en el código de frontend y volver a crear el Service de frontend.
Resultados y Conclusiones
- El resultado de este laboratorio es una aplicación web simple, distribuida y desacoplada, formada por tres microservicios en contenedores Docker sobre la nube de AWS, apoyada en servicios administrados de AWS para la orquestación de contenedores y la gestión de imágenes.
- La solución desplegada no es production ready: tiene brechas importantes de seguridad, escalabilidad y alta disponibilidad, y limita una gestión operativa efectiva — lo cual va en contra del AWS Well-Architected Framework. Sin embargo, para efectos de aprendizaje y experimentación cumple su propósito y es un paso intermedio hacia la implementación de una solución más robusta, segura y escalable.
- Como profesional de IT liderando proyectos y operaciones de infraestructura, es muy valioso poder experimentar y entender de primera mano los pasos fundamentales para el despliegue de este tipo de soluciones y arquitecturas. Teniendo esta base, es posible replicarla en soluciones con lógica mucho más compleja, pero los cimientos son los mismos.