Main Concept
Previously, each foundation model was designed for a specific output type — “text-only” like GPT-3, “image-only” like DALL-E, or “speech-only” like Whisper. The current trend is to build multimodal models that can process multiple types of input and, ideally, generate multiple types of output.
Three Levels of Multimodality
1. Multimodal Input (Text Output)
Accepts multiple input types but generates text only. These are the most common today.
- Examples: Amazon Nova Pro, Claude 3, GPT-4 Vision
- Use case: “Here’s an image and a question — describe what you see”
2. Specialized Output Models
Accept input (usually text) and generate one specific non-text output type:
- Images: Amazon Nova Canvas, DALL-E 3, Stable Diffusion, Midjourney
- Video: Amazon Nova Reel, Runway Gen-2, Pika Labs
- Audio/Music: MusicGen, AudioCraft
- Speech: Amazon Nova Sonic, ElevenLabs
3. Truly Multimodal (Input + Output)
Can understand and generate multiple data types. Still emerging — Gemini is the closest example today (text + images), though with limitations.
Foundation Model vs. AI Model
A regular AI model is typically specialized for a specific task or domain. A Foundation Model is different:
- Trained on massive, diverse datasets (billions+ of examples)
- General-purpose — can be applied across many tasks without retraining
- Versatile enough to write, generate images, solve math, answer questions, engage in dialogue, and write code
Examples: GPT-4, Claude, Stable Diffusion, Amazon Titan, Bloom.
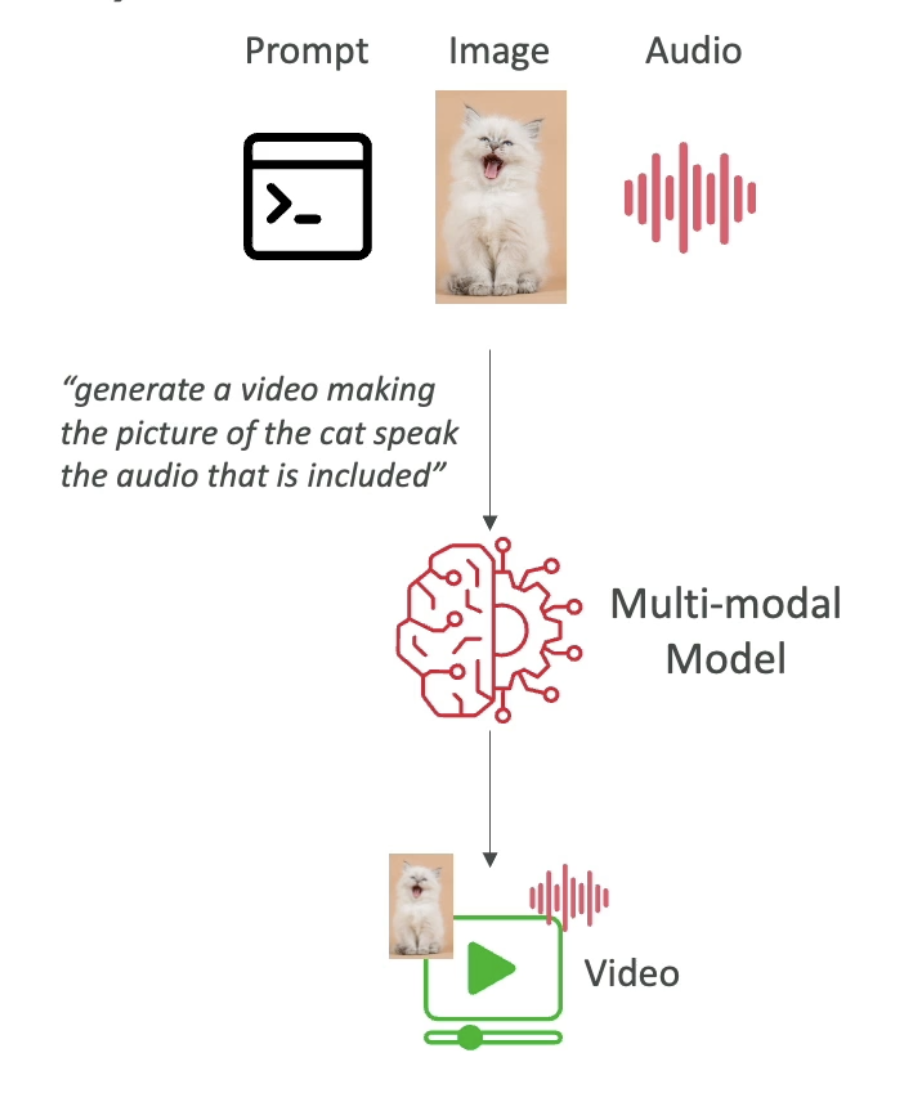
Use Case Example
A multimodal model can take a mix of text, images, and audio as input — and return a mix of text and video as output. The model understands context across modalities rather than treating each input type in isolation.
AIF-C01 Exam Relevance
Exam tip: Know the three levels. The exam commonly asks you to identify which model type fits a given scenario — e.g., “analyze an image and answer a question about it” → multimodal input model. “Generate a product image from a description” → specialized image output model (diffusion-based).
Key AWS multimodal models to recognize:
| Model | Type | Modality |
|---|---|---|
| Amazon Nova Pro | Multimodal input | Text + Image + Video → Text |
| Amazon Nova Canvas | Specialized output | Text → Image |
| Amazon Nova Reel | Specialized output | Text → Video |
| Amazon Nova Sonic | Specialized output | Text → Speech |
| Claude 3 / Claude 4 | Multimodal input | Text + Image → Text |