Metrics used for Model Evaluation
Main Concept
When performing an automated evaluation of foundation models, there are commonly used generic metrics for evaluating the output of such models, this metrics give numerical results about different things we would like to measure.
Context
Metrics are important because allow for objective measurement with quantifiable, reproducible results, removing the subjectivity on “how well does the model works?” and allow us to build reliable AI systems.
Key Aspects
Overview of the main automated metrics for evaluating foundational models:
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
- Designed to evaluate text summaries and machine translations
- Compares the generated summary with a reference summary
- There are two variants which measure different things:
- ROUGE N - measures the number of n-grams (aka words) that match between the generated summary and the reference summary
- ROUGE L - measures the longest matching sequence between the generated summary and the reference summary.
BLEU (Bilingual Evaluation Understudy)
- It’s designed to evaluate automatic translation, but is also used for other tasks
- It compares the generated translation with a reference translation
- It measures the number of n-grams (words) that match, and gives scores from 0 to 100.
- It considers precision and penalize brevity.
BERTScore
- It evaluates the semantic (meaning) similarity between generated texts, rather than word-to-word comparison. For instance, ‘cat’ and ‘feline’ are different words but are semantically equivalent.
- It uses an auxiliary pre-trained model called BERT (Bidirectional Encoder Representations from Transformers) to compare the contextualized vector representation (called embeddings) of those texts and mathematically calculates their similarity.
Perplexity
- It measure how well the model predicts the next token (lower scores are better)
- A lower perplexity means the model is more confident and accurate on its predictions.
NOTE
Metrics are normally used together to evaluate a model from different perspectives, as they measure different things.
Example
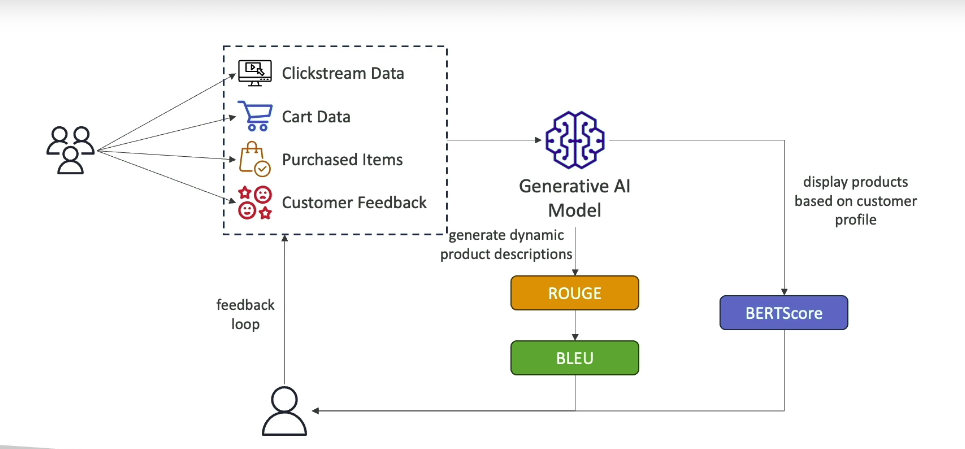
Conclusions
- What I take away from this topic is that language models must undergo rigorous evaluation processes, which include hard metrics to detect not only the quality of the model but also any type of bias or lack of impartiality that may be introduced, and this becomes even more critical today, when most people, including children, “acquire knowledge” through chatbots such as ChatGPT.
Related Concepts:
Links:
References