RAG and Knowledge Bases with Amazon Bedrock
Main Concept
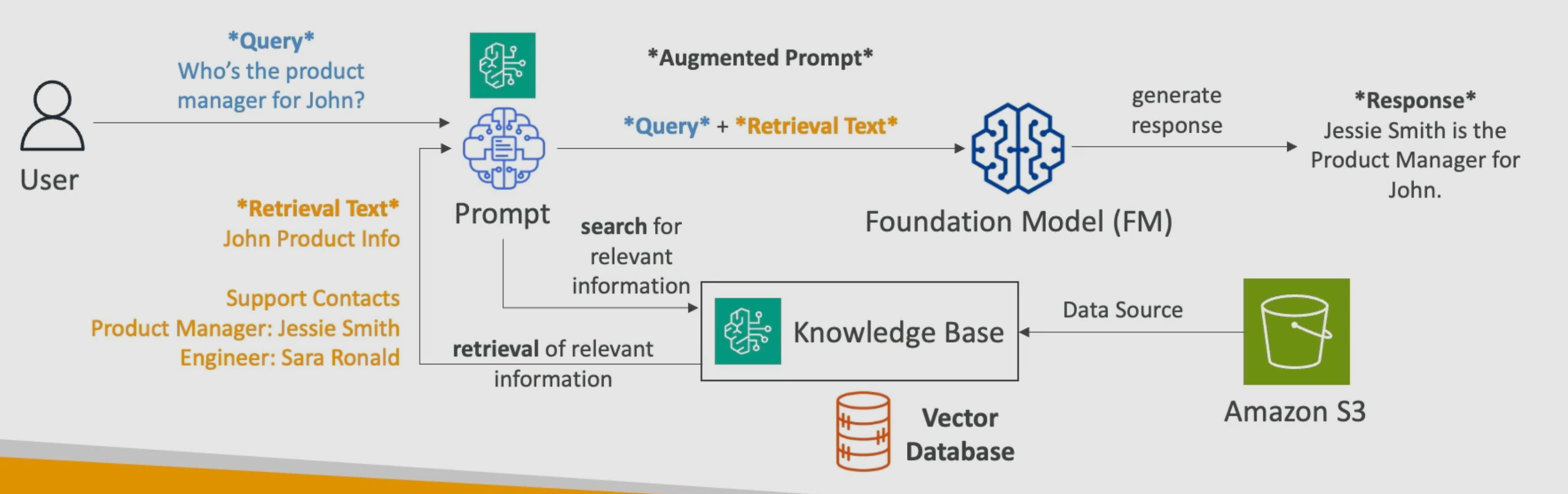
Amazon Bedrock has the capacity to manage knowledge bases used to apply RAG and expand foundation model information. Knowledge bases are built and managed by Amazon Bedrock from data stored in data sources such as Amazon S3.
How it works?
- The user makes a query (prompt), for example: “Who is John Doe working with?“.
- Bedrock converts the query into an embedding (vector) using an embedding model (e.g., Amazon Titan Embeddings) and searches the Knowledge Base for semantically similar chunks. For example, the retrieved text could be something like this:
## Product ERP team
- John Doe (Product Manager)
- Jessie Smith (Engineering Manager)
- Sara Ronald (Engineer)
- The retrieved text is then used as context (injected) along with the original query to the model. This is known as the Augmented Prompt.
- The model uses both the retrieved context and its general knowledge (or only the context, depending on the configuration) to generate the response, for instance:
John is working with Jessie Smith and Sara Ronald as part of the ERP product team
Key Aspects
- With RAG, the foundation model gains access to up-to-date or proprietary data without requiring retraining. The freshness of that data depends on how frequently the knowledge base is synced.
- In Amazon Bedrock, Knowledge Bases are built through Vector Databases. Bedrock uses a dedicated embedding model (selectable, e.g., Amazon Titan Embeddings) to generate vectors and manages the database, enabling efficient retrieval of information.
- Multiple options exist for vector databases, including native AWS services such as Amazon OpenSearch Service, Amazon Aurora, Amazon Neptune, Amazon DocumentDB, and Amazon RDS for PostgreSQL, as well as external options like MongoDB, Redis, and Pinecone.
- Multiple options exist for data sources, including Amazon S3, Confluence, Microsoft SharePoint, Salesforce, and web pages.
About Embedding Generation in Bedrock
Bedrock uses a dedicated embedding model (e.g., Amazon Titan Embeddings) to generate the vectors stored in the Knowledge Base. You select this model during setup. This level of detail is beyond the scope of the exam, but it is useful context to understand how RAG works end-to-end.
Applications
Applications include customer service chatbots, legal document search tools, medical consultation systems, and others.
Summary/Conclusion
In Amazon Bedrock, you can feed a knowledge base in several ways: by uploading documents to S3, or by connecting it to services like Confluence, SharePoint, Salesforce, etc. Bedrock handles the creation of a vector database (through a chunking and embedding process), which it uses to retrieve data and augment the user’s prompt (RAG). Multiple options exist for the “engine” behind these databases, and the choice depends on the use case.