Main Concept
RLHF is a model training technique used for fine-tuning large models, where human feedback is used to help ML to self-learn more efficiently.
Key Aspects
- Unlike Reinforcement Learning, where the reward function is purely logical
or mathematical, in RLHF we directly incorporate real human feedback into
that reward function — allowing the model to align more closely with human
goals, desires, and values. - First, the model’s responses are compared to human’s responses
- Then, a human assess the quality of model’s responses
- RLHF is used throughout GenAI applications including MML models.
- RLHF significantly enhances the model performance
Examples
- Grading text translation from “technically correct” to “human”
Training Methodology using RLHF
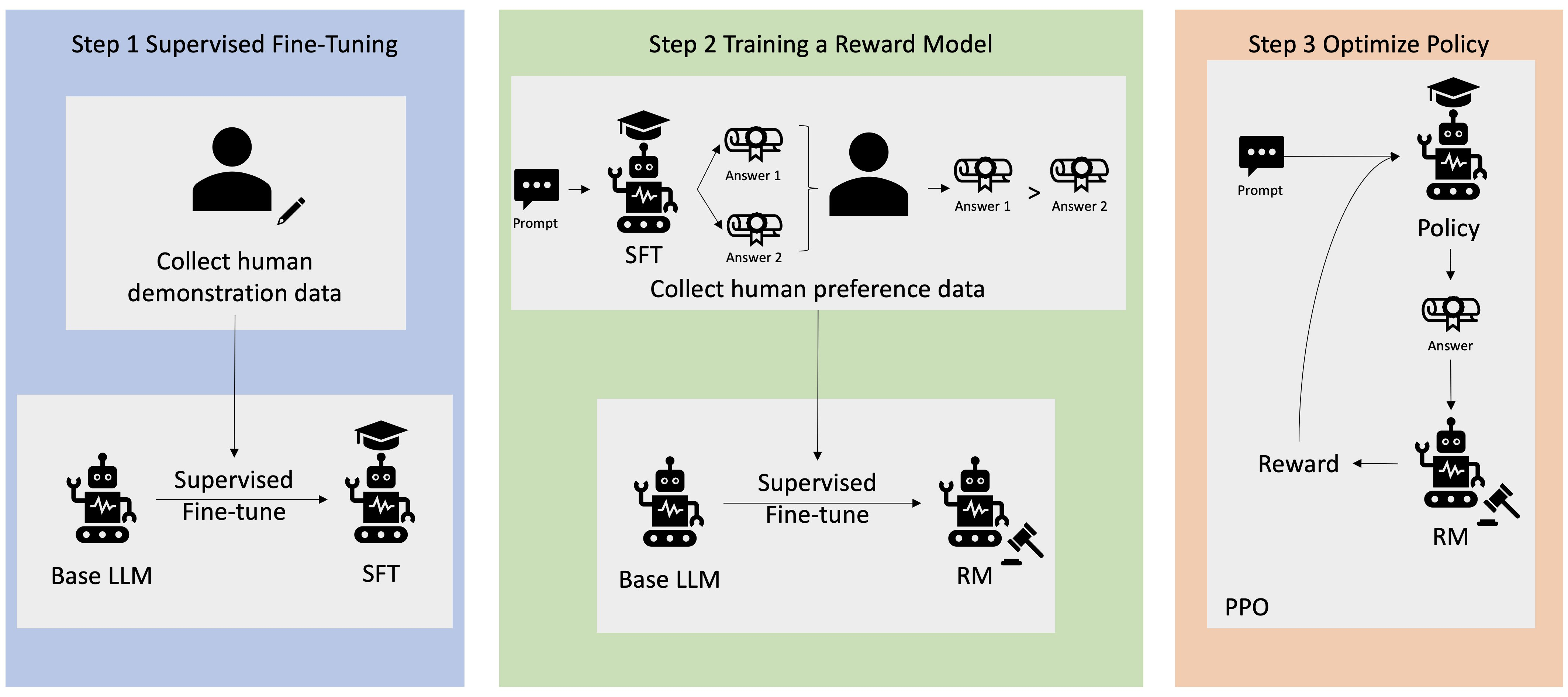
This is the high-level process used to train a model using RLHF:
The goal: Build a chatbot that answers internal company questions the way a human expert would.
Step 1: Data Collection
- In this step, we build the training dataset, which consist of several question-answer pairs created manually by humans.
- Those answers are the gold standard human answer for each question that we would expect the model to answer the same or similarly.
- Q: “Where is the HR department in Boston?”
- A: “3rd floor, Building A”
Step 2: Supervised Fine-tuning
- Here we take an existing base model and fine-tune it with our internal data.
- Now the model generates its own answers to those same questions.
- Its answers are mathematically compared to the human answers.
- The model learns to get closer to human-quality responses
At this point we have a decent model - but “mathematically close” doesn’t always mean “what a human would actually prefer”
Step 3: Build a Rewards Model
- We show humans TWO responses to the same prompt.
- “Which answers do yo prefer - A or B?”
- Human picks their preference repeatedly across many examples.
- A separate model (the reward model) learn from those preferences
- It can how predict “how much would a human like this response?” without needing a human present every time.
This the key innovation of RLHF - you’re essentially training a model to simulate human judgment.
Step 4: Optimize with the Reward Model
- Now we use the reward model as an automated judge.
- The language model generates responses.
- The reward model scores them.
- The language model adjust to score higher
- This loop runs fully automated meaning no humans needed at this stage.
The complete picture
- Human answers → fine-tune model (Step 2)
- Human preferences → train reward model (Step 3)
- Reward model → optimize language model (Step 4)
Exam Domains
Domain 3, Task Statement 3.3.