Main Concept
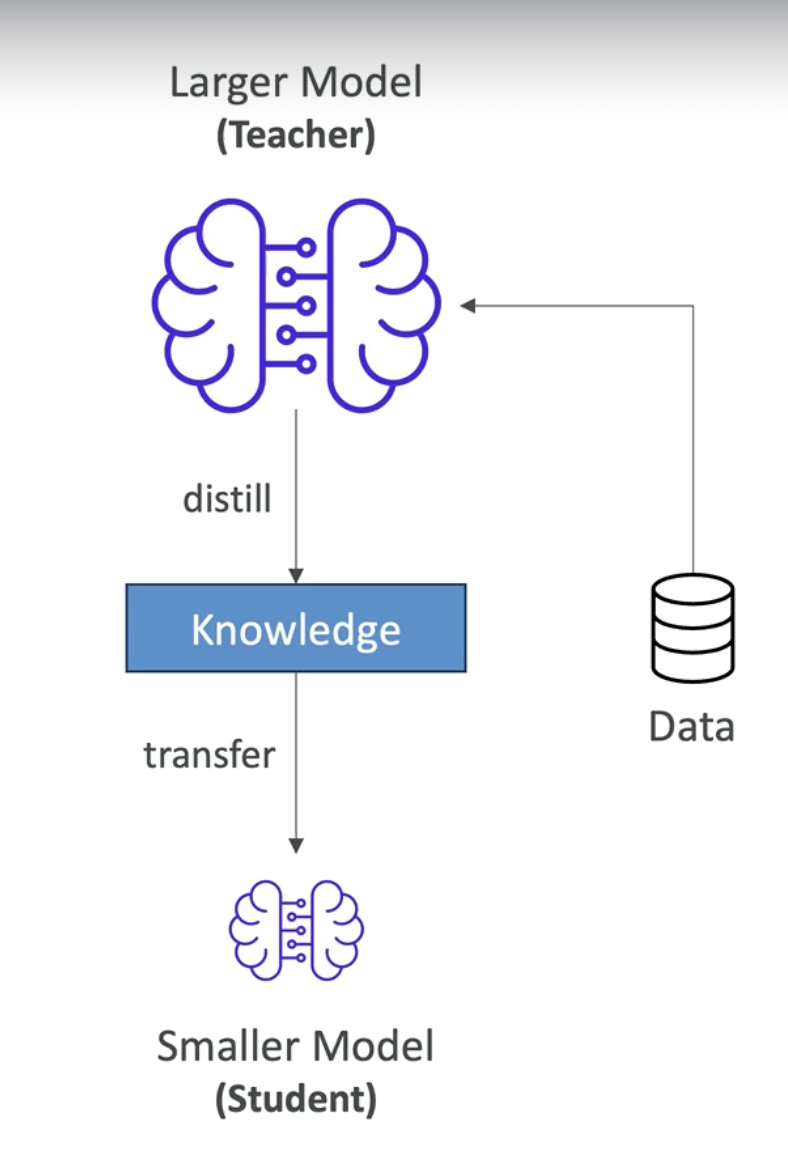
It is a technique in which a pre-trained model is taken and its knowledge is transferred to a new, smaller model. The large model is called the teacher and the small model is called the student.
Why it matters
You get 80% of the performance at 20% of the cost/speed. Useful when you need efficiency without full capability loss.
Key Points
- It does not fall into the Model Customization method.
- The student model is smaller and faster, therefore more cost-effective (up to 75% cheaper)
- Its accuracy is reduced, but it could still be acceptable.
- You collect input and output data from the teacher model (e.g. prompts and their respective answers), then you transfer (distill) this data to the student model. This will create a smaller model which will behave similarly to the original model.
- The student model learns to replicate the behavior of the teacher model, not just memorize input/output pairs.
Graphical Explanation
Examples
Real example:
- Teacher model (Claude 3 Opus): 176 billion parameters, slow, expensive
- Collect: 10,000 prompts with their answers from Claude
- Student model (Claude 3 Haiku): 8 billion parameters, fast, cheap
- Result: Much faster/cheaper model that behaves similarly