Main Concept
Bias is the difference (error) between what the model predicts and the actual
value. It occurs when the model makes wrong assumptions during the ML process —
typically by being too simple to capture the real pattern in the data.
Key Aspects
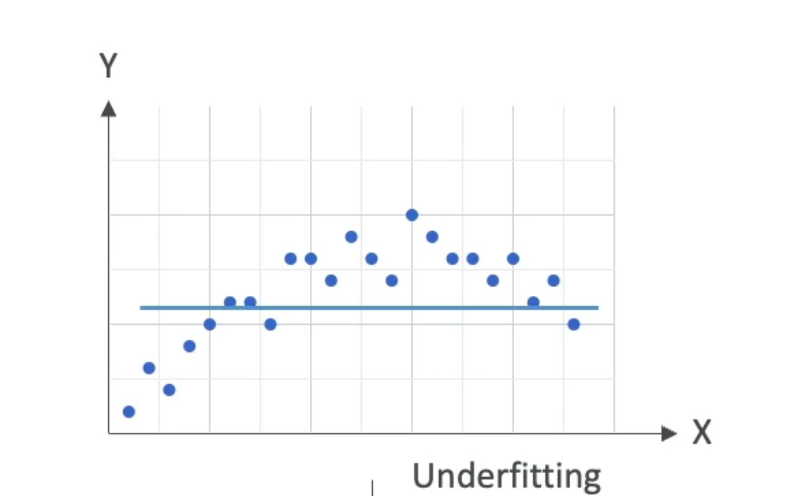
High Bias = Underfitting
- The model doesn’t closely match even the training data.
- It oversimplifies — for example, fitting a straight line to a non-linear
dataset. - The model has learned the wrong pattern, or no pattern at all.
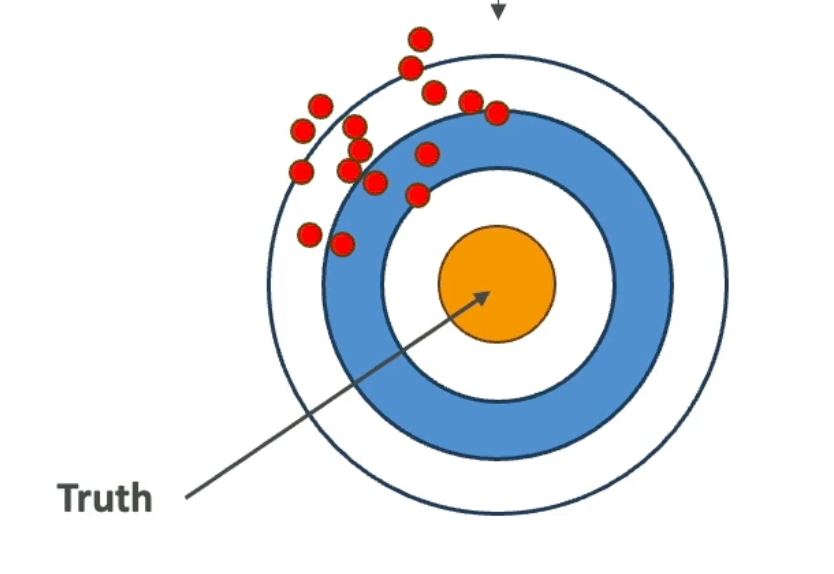
**The target diagram
- The center (orange) = the truth (the correct prediction).
- The red dots = the model’s predictions.
- High bias means all predictions are consistently off-center — the model
is systematically wrong, not randomly wrong. The predictions cluster
together but far from the truth.
How to reduce bias
- Use a more complex model (give it more capacity to learn).
- Increase the number of features (give it more information to learn from).
Relationship to Variance
Bias and variance are two sides of the same problem:
| Bias | Variance | |
|---|---|---|
| Also known as | Underfitting | Overfitting |
| Problem | Model too simple | Model too complex |
| Training performance | Poor | Great |
| New data performance | Poor | Poor |
| Fix | More complexity | Less complexity / more data |
Exam Domain
- Domain 1, Task Statement 1.1: “bias” as a basic AI term.
- Domain 4, Task Statement 4.1: “understand effects of bias and variance
(for example, effects on demographic groups, inaccuracy, overfitting,
underfitting).”
Important Distinction for the Exam
The word “bias” appears in two different contexts in this exam — don’t confuse them:
- Model bias (this note) → statistical concept, model underfits the data.
- AI bias (Domain 4) → ethical concept, model produces unfair or
discriminatory outputs toward certain demographic groups.
Both are in the exam. They are related but distinct concepts.
Related Notes
- Model Fit
- Variance
- Feature Engineering
- Responsible AI / AI Bias