Main Concept
A machine learning project follows an iterative lifecycle of phases — from identifying a business problem to continuously improving a deployed model. Understanding this lifecycle is essential for recognizing which tools, techniques, and AWS services apply at each stage.
The Phases
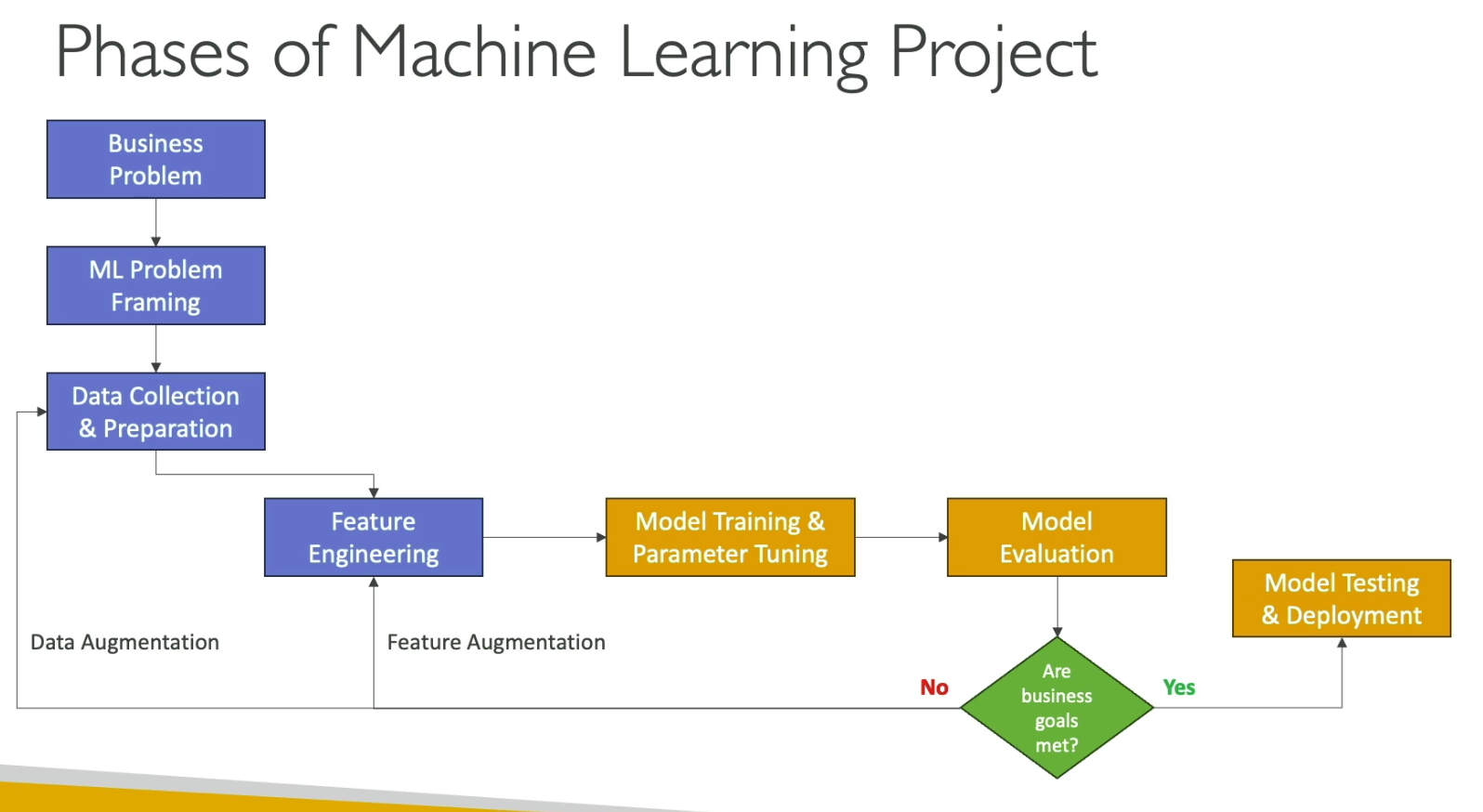
1. Define business goals ↓
2. Frame as ML problem ↓
3. Data collection & preparation ↓
4. Feature engineering ↓
5. Model training ↓
6. Hyperparameter tuning ↓
7. Model evaluation ↓
8. Are business goals met? NO → back to step 3 (more/better data) or step 5 (retrain) YES ↓
9. Deploy ↓
10. Monitor & debug ↓
11. Collect new predictions → feed back into step 3 (retrain loop)
Phase Details
1. Define Business Goals
- Stakeholders define value, budget, and success criteria.
- Define a KPI (Key Performance Indicator) to measure success.
- This is a business decision, not a technical one.
2. Frame as ML Problem
- Determine whether ML is actually an appropriate solution — sometimes it is not.
- Convert the business problem into an ML problem.
- Data scientists, data engineers, ML architects, and subject matter experts (SME) collaborate here.
3. Data Collection & Preparation
- Collect data and convert it into a usable format.
- Make it centrally accessible in one place.
- Includes pre-processing and data visualization.
- EDA (Exploratory Data Analysis) happens here — explore data, compute statistics, visualize distributions, build correlation matrices to understand which features are relevant and how they relate to each other.
4. Feature Engineering
- Create, transform, and extract variables (features) from the raw data.
- If results are unsatisfactory: data augmentation (more data) or feature augmentation (better features).
5. Model Training
- Train the model on the prepared dataset.
- Very iterative — feeds back into data processing continuously.
6. Hyperparameter Tuning
- Adjust the parameters that define how the algorithm works.
- Not the same as model parameters learned during training — these are set by the engineer before/during training.
7. Model Evaluation
- Evaluate the model against test datasets.
- Ask: are business goals met?
- Use performance metrics (Accuracy, F1, AUC for classification) and business metrics (ROI, cost per user, customer feedback).
8. Deployment
- Select the appropriate deployment model:
- Real-time inference
- Batch inference
- Serverless
- Asynchronous
- On-premises / edge
- Model is now ready to make predictions for users.
9. Monitoring & Debugging
- Deploy a system to check if the model operates at the desired performance level.
- Enables early detection and mitigation of problems.
- Watch for model drift — model performance degrades over time as the real world changes (example: clothing trends change, model becomes irrelevant).
10. Continuous Improvement (Retraining Loop)
- Correct predictions are added back to the training dataset.
- Model is periodically retrained with new data.
- Requirements may change over time — continuous iteration is essential.
Key Concept: The Iterative Nature
- This is not a linear process — it is a loop. Data processing and model development are deeply intertwined and feed into each other continuously.
- After deployment, new prediction data feeds back into the beginning of the cycle.
AWS Services by Phase
| Phase | AWS Service |
|---|---|
| Data collection & prep | AWS Glue, AWS Glue DataBrew, Amazon S3 |
| EDA & feature engineering | Amazon SageMaker Data Wrangler, SageMaker Feature Store |
| Model training & tuning | Amazon SageMaker |
| Model evaluation | Amazon SageMaker, SageMaker Clarify |
| Deployment | Amazon SageMaker (endpoints) |
| Monitoring | Amazon SageMaker Model Monitor, Amazon CloudWatch |
| Human review | Amazon Augmented AI (A2I) |
What is Out of Scope for This Exam
The exam does NOT ask you to:
- Implement feature engineering techniques
- Perform hyperparameter tuning
- Build or deploy ML pipelines
- Conduct mathematical or statistical analysis
You only need to describe the components and identify the relevant AWS services for each stage.
Exam Domain
- Domain 1, Task Statement 1.3: “Describe the ML development lifecycle”
- Describe components of an ML pipeline (data collection, EDA, pre-processing, feature engineering, model training, hyperparameter tuning, evaluation, deployment, monitoring).
- Identify relevant AWS services for each stage.
- Understand fundamental concepts of MLOps (experimentation, repeatable processes, model monitoring, model re-training).
- Understand model performance and business metrics to evaluate ML models.
Related Notes
- EDA - Exploratory Data Analysis
- Feature Engineering
- Hyperparameter Tuning
- Model Fit - Overfitting and Underfitting
- Binary Classification Metrics
- Regression Metrics
- Inferencing
- MLOps
- Model Drift
- Amazon SageMaker
- Amazon SageMaker Model Monitor
- Amazon SageMaker Feature Store
- Amazon SageMaker Data Wrangler
- Amazon Augmented AI (A2I)