Main Concept
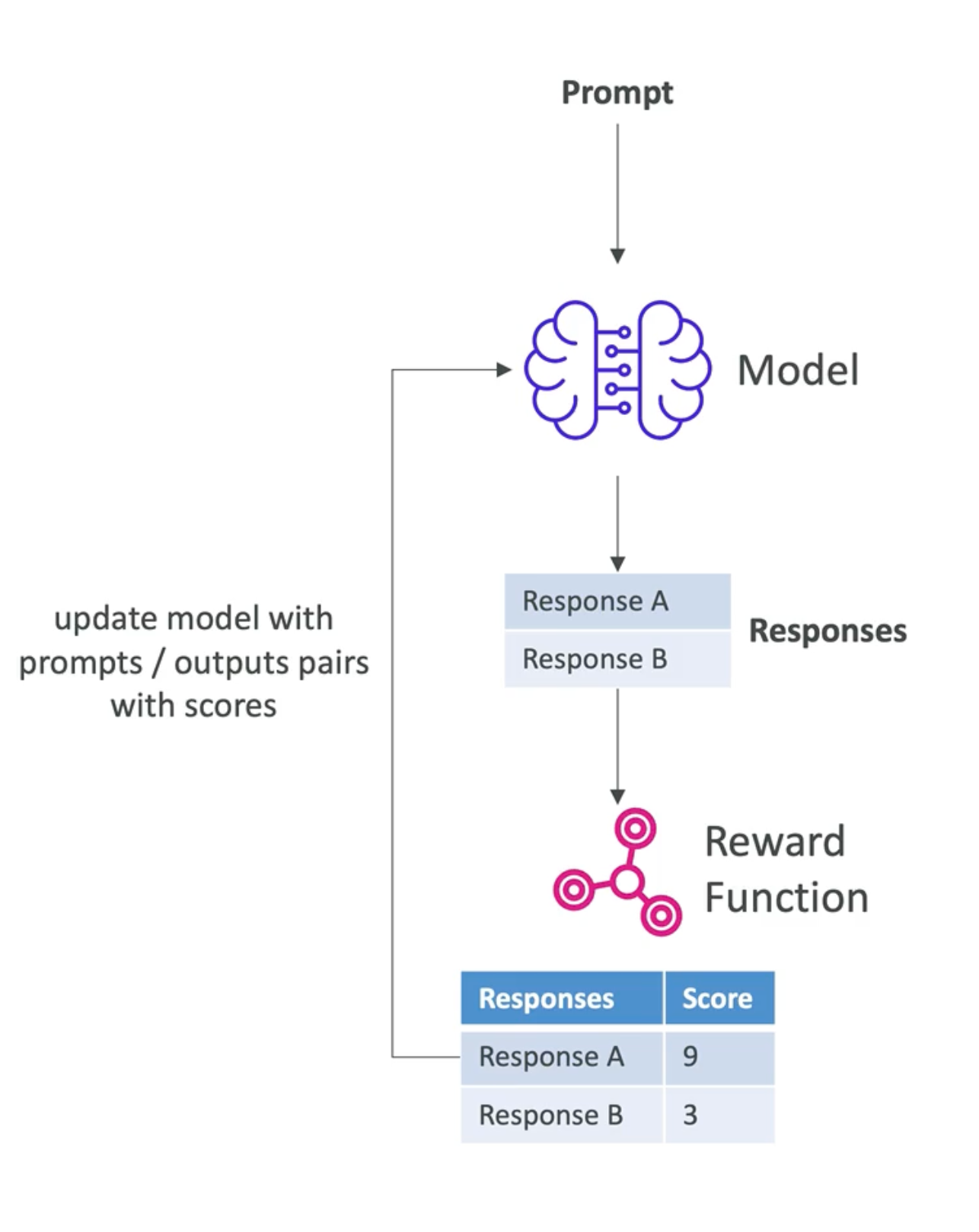
Reinforcement Fine-Tuning is the process to improve an existing foundation model using feedback-based learning, that means you ask questions or tasks to the model and depending on the answer it receives feedback (rewards or penalties), so the model will learn which answer is better for the next time.
Context
Reinforcement Fine-Tuning solves the problem of manual labeling data and real-world feedback information not being used. However, it requires a solid and well-designed feedback mechanism (reward function). Its advantages include cost and speed, relevance (real human behavior), scalability, and continuous improvement.
Key Aspects
- If the answer or output is numerical or objective, you can use a reward function which can be implemented on an AWS Lambda to score the response.
- If the answer or output is more subjective or more abstract, you can use even another model to assess the answer. This is called a judge model or evaluator model
- When a real human intervenes in the process, this is called Reinforcement Learning from Human Feedback or RLHF.
- The model learns iteratively through the results of reward functions and will attempt to achieve higher scores over time.
Graphic Explanation
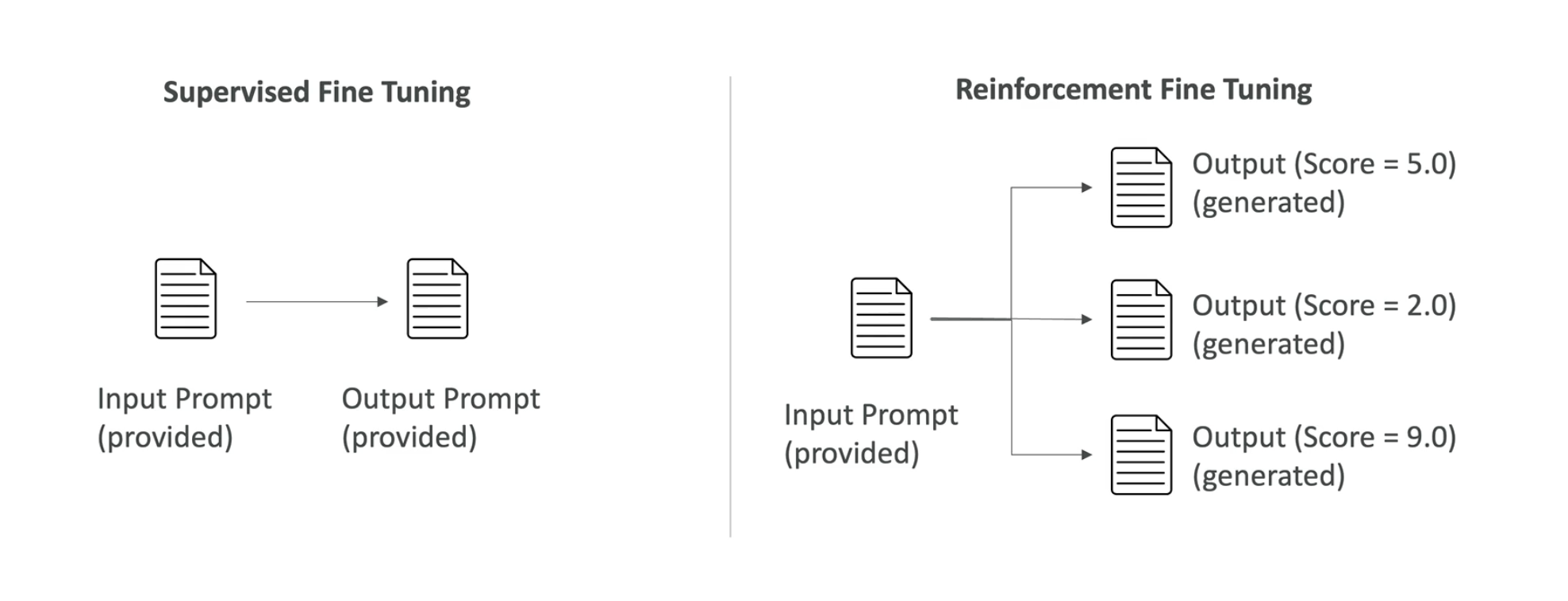
Supervised Fine Tuning Vs Reinforcement Fine Tuning
Real-World Examples
E-commerce Product Recommendation system
We have a recommendation model which puts 5 products in a banner, based on the product your viewing of the last 10 product you purchased. The model is rewarded according to what the customer does: if the customer buys a product, certain points are given; if they only click but don’t buy, fewer points are given; if they buy more than one product, even more points are given.
Over time, the model starts to recognize patterns and which combination of products gives them more points, etc., so it starts making better suggestions.
This is an example of objective responses, but the same principle can we apply to subjective tasks where the rewards will be evaluated by another model or even a human!
Critical Questions
- How long will it take for a model to iterate to actually improve?
- What happens if the training model has biases?
Related Concepts:
- Model Customization
- Model Customization with Amazon Bedrock
- Model Fine-Tuning
- Supervised Fine-Tuning
Links:
References