Main Concept
Training data is the foundation of any ML or AI model. The quality and characteristics of training data directly determine model performance. As the saying goes: garbage in, garbage out — if your training data is poor, your model will be poor.
Training data is arguably the most critical stage in building a good model. Before choosing algorithms or frameworks, you must first understand what data you have and what you’re trying to predict.
Data Types by Structure
Labeled Data (Supervised Learning)
- Data with known correct answers/labels
- Example: photos of cats labeled “cat”, photos of dogs labeled “dog”
- Used for: Classification, regression
- More expensive to obtain (requires human labeling)
- Use case: Supervised Learning, where the model is trained to map inputs to known outputs

Unlabeled Data (Unsupervised Learning)
- Data without pre-assigned labels
- Example: raw customer purchase histories
- Used for: Clustering, dimensionality reduction, anomaly detection
- Cheaper to obtain but harder to use
- Use case: Unsupervised Learning where the model tries to find patterns or structure the data

Structured Data
- Organized in rows and columns (databases, spreadsheets)
- Example: customer age, income, purchase history
- Machine learning algorithms work well with this
- Traditional ML (SVM, XGBoost) excels here
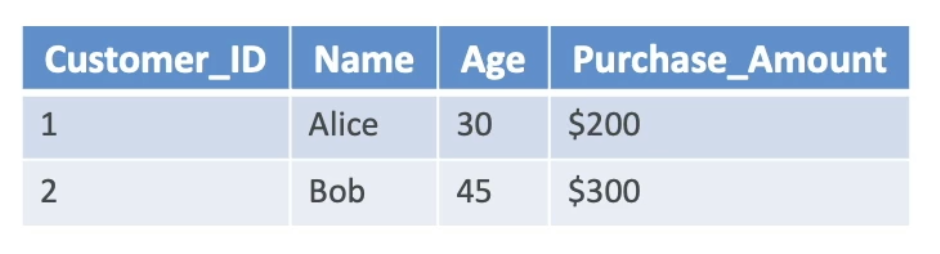
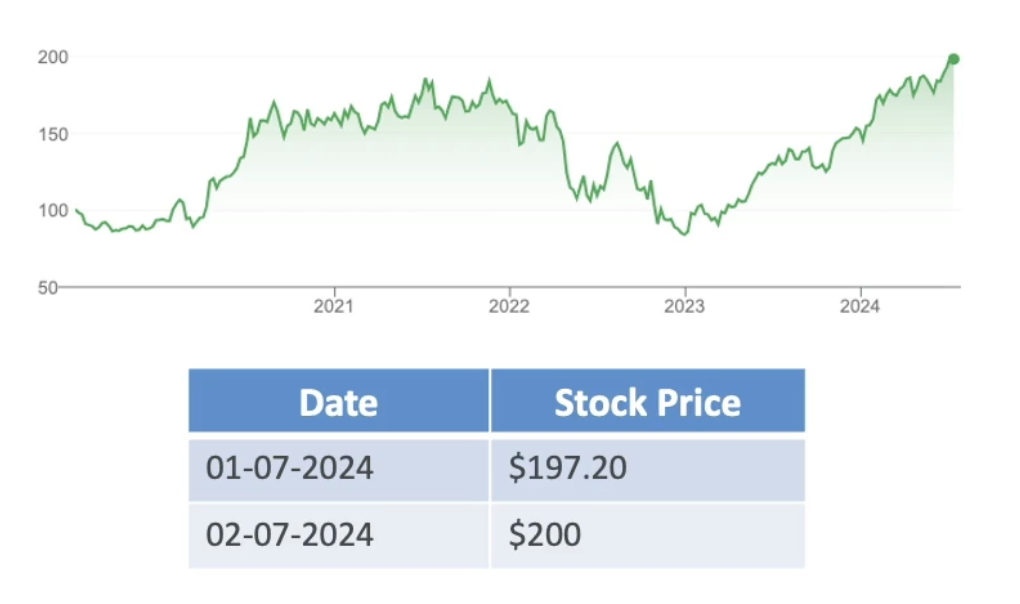
- One type of structure data is Time Series Data, data points collected or recorded at successive point times.
Unstructured Data
- No predefined format (text, images, audio, video)
- Example: customer reviews, photos, videos
- Requires special handling and deep learning
- GenAI models work with this
Data Characteristics That Matter (AIF-C01)
| Characteristic | Impact |
|---|---|
| Size | More data generally = better performance (but quality > quantity) |
| Diversity | Representative of real-world scenarios reduces bias |
| Balance | Unbalanced classes (e.g., 99% class A, 1% class B) skews predictions |
| Cleanliness | Missing values, outliers, errors degrade model performance |
| Recency | Stale data may not reflect current patterns |
| Bias | Biased training data produces biased models |
The Data Preparation Pipeline
Training data must be prepared before it can be used. See Data Preparation for the specific steps: curation, labeling, quality checks, and bias assessment.
AIF-C01 Exam Relevance
The exam explicitly asks about:
- Identifying data types (labeled/unlabeled, structured/unstructured)
- Understanding how data characteristics affect model selection
- Recognizing when data is insufficient, biased, or unrepresentative
- Distinguishing between pre-training data and fine-tuning data
Exam tip: A question about “why did my model fail?” often comes down to data quality, not algorithm choice.