Main Concept
Machine Learning is a subfield of Artificial Intelligence that focuses on systems that can “learn” from data and make predictions or decisions based on that data. Instead of programming explicit rules, ML models are trained on examples — once trained, the model can generalize and make predictions on new, unseen data.
Context
Traditional programming requires humans to explicitly define rules for every scenario (IF condition THEN action). But many real-world problems are too complex, too variable, or simply too large to cover with hand-written rules.
Machine Learning flips the paradigm: instead of programming rules, we provide examples and let the system discover the patterns on its own.
IMPORTANT
AI ≠ Machine Learning ML is a subset of AI — not all AI is ML. Most modern AI happens to be ML-based, but not all of it.
A classic example of AI that is not ML: Expert Systems. MYCIN (developed in the 1970s) could diagnose patients based on reported symptoms and test results using a collection of over 500 hand-crafted IF-THEN rules with associated probabilities. No learning from data — pure rule encoding. It was never widely deployed in production partly because the hardware of the time couldn’t support it at scale.
ML Techniques
The main categories of Machine Learning, relevant for AIF-C01:
-
Supervised Learning — trains on labeled data; the model learns the mapping from inputs to known outputs.
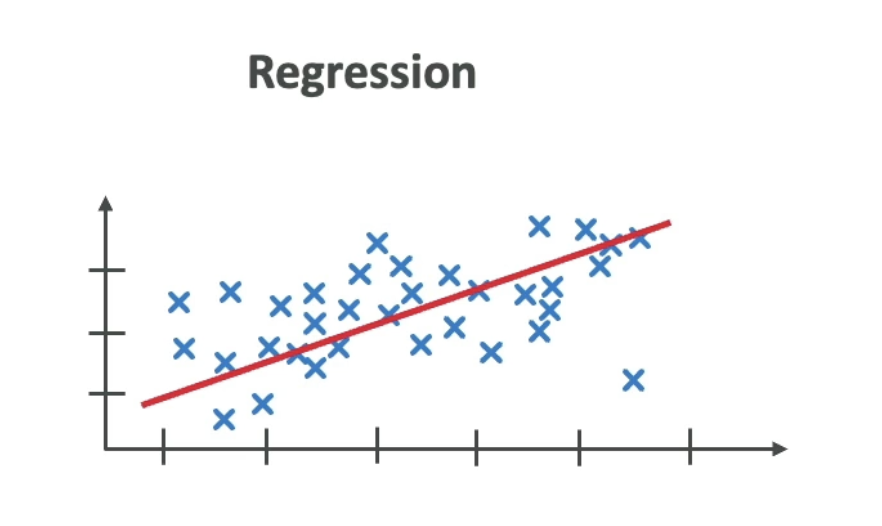
- Regression — predicts a continuous numeric value (e.g., house price, temperature)
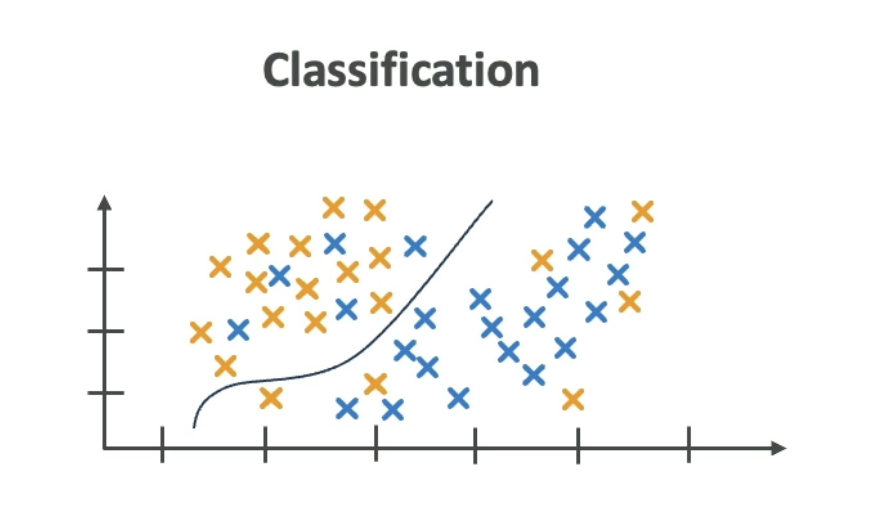
- Classification — predicts which category something belongs to (e.g., spam/not spam, cat/dog)
-
Unsupervised Learning — trains on unlabeled data; the model discovers hidden structure on its own.
- Clustering — groups similar data points (e.g., customer segmentation)
- Anomaly detection — identifies outliers (e.g., fraud detection)
-
Reinforcement Learning — an agent learns by interacting with an environment and receiving rewards or penalties. No labeled dataset; learning happens through trial and error.
-
Semi-supervised Learning — uses a small amount of labeled data combined with a large amount of unlabeled data. Practical when labeling is expensive.
-
Self-supervised Learning — the model generates its own labels from the input data. Common in foundation model pre-training (e.g., predicting the next word in a sentence).
Examples
Regression
Predicts a continuous output — e.g., given square footage, location, and number of rooms, predict the sale price of a house.
Classification
Predicts a discrete category — e.g., given an email’s content and metadata, classify it as spam or not spam.