Main Concept
Unsupervised Learning is a machine learning approach where the model trains on unlabeled data — there are no correct answers provided. The goal is to let the model discover patterns, structures, or relationships inherent in the data on its own.
The machine groups and organizes the data by itself, but humans still assign meaning to the output. For example, a model might cluster thousands of images of cats together without knowing what a cat is — a human then labels that cluster “cats.”
Contrast with Supervised Learning, where labeled input-output pairs teach the model what to predict.
How It Works
- Raw, unlabeled data is fed to the model
- The model identifies structure — similarities, groupings, or anomalies — without guidance
- Humans interpret and label the discovered groups or patterns
Core Techniques
| Technique | Purpose | Example |
|---|---|---|
| Clustering | Group similar data points together | Customer segmentation by purchase behavior |
| Association Rule Learning | Find relationships between variables | ”Customers who buy X also buy Y” |
| Anomaly Detection | Identify data points that don’t fit the pattern | Detect fraudulent transactions |
Example
Plot customer data on two axes (e.g., income vs. spending score). Without any labels, the data naturally separates into visible clusters. Unsupervised learning algorithms like K-Means find those clusters automatically.

After clustering, each group can be treated as a distinct segment:
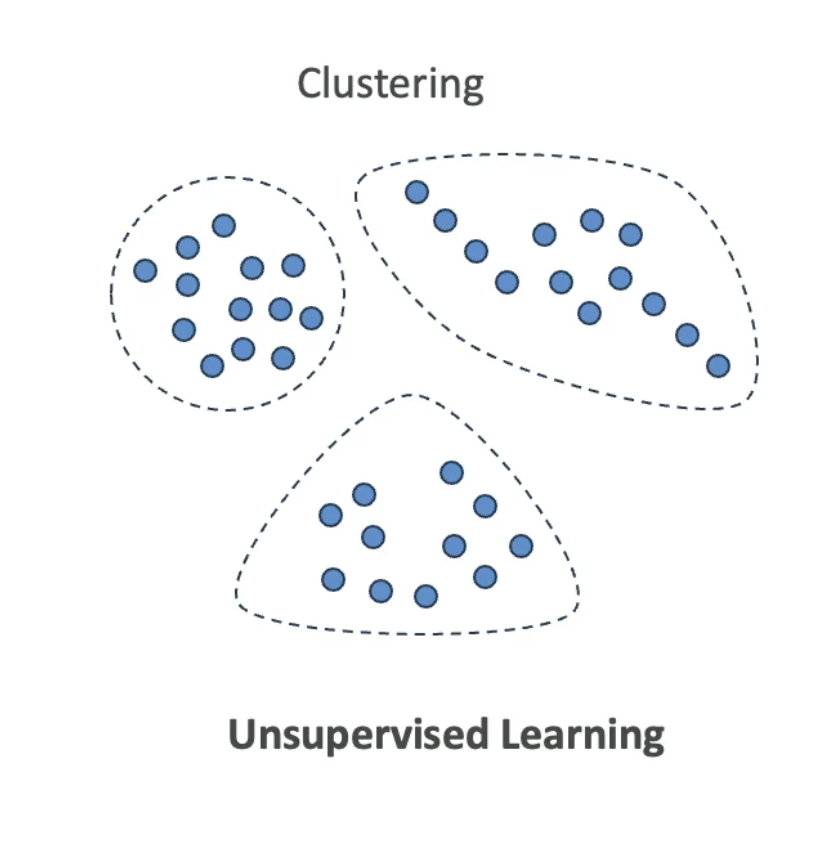
Those clusters can then be used for:
- Targeted marketing — different campaigns for each segment
- Recommendation systems — suggest products popular within a segment
Key Aspects
- Feature Engineering can significantly improve the quality of what the model discovers — better-represented data leads to more meaningful clusters or patterns.
- Works well when you have large amounts of data but labeling it manually is impractical or expensive.
- Output requires human interpretation — the model finds structure, but meaning comes from domain expertise.
AWS Services
Amazon SageMaker includes built-in algorithms for unsupervised tasks:
- K-Means — clustering
- Random Cut Forest — anomaly detection
- LDA (Latent Dirichlet Allocation) — topic modeling in text
Related Concepts
- Supervised Learning
- Machine Learning (ML)
- Deep Learning (DL)
- Feature Engineering
- Data Types and Formats in AI
- Amazon SageMaker Overview
Exam Domain (AIF-C01)
Domain 1 — Fundamentals of AI and ML
- Task Statement 1.1: Explain basic AI concepts — types of ML (supervised, unsupervised, reinforcement learning).
- Task Statement 1.3: Describe the ML development lifecycle — understanding when to apply unsupervised approaches.
Links
References