Main Concept
Clustering is an Unsupervised Learning technique used to group similar data points together into clusters based on their features. The model identifies the groups on its own — humans then interpret what each group represents.
How It Works
- Feed unlabeled data into the model
- The algorithm measures similarity between data points
- Data points that are close together get grouped into the same cluster
- Humans label and interpret what each cluster means
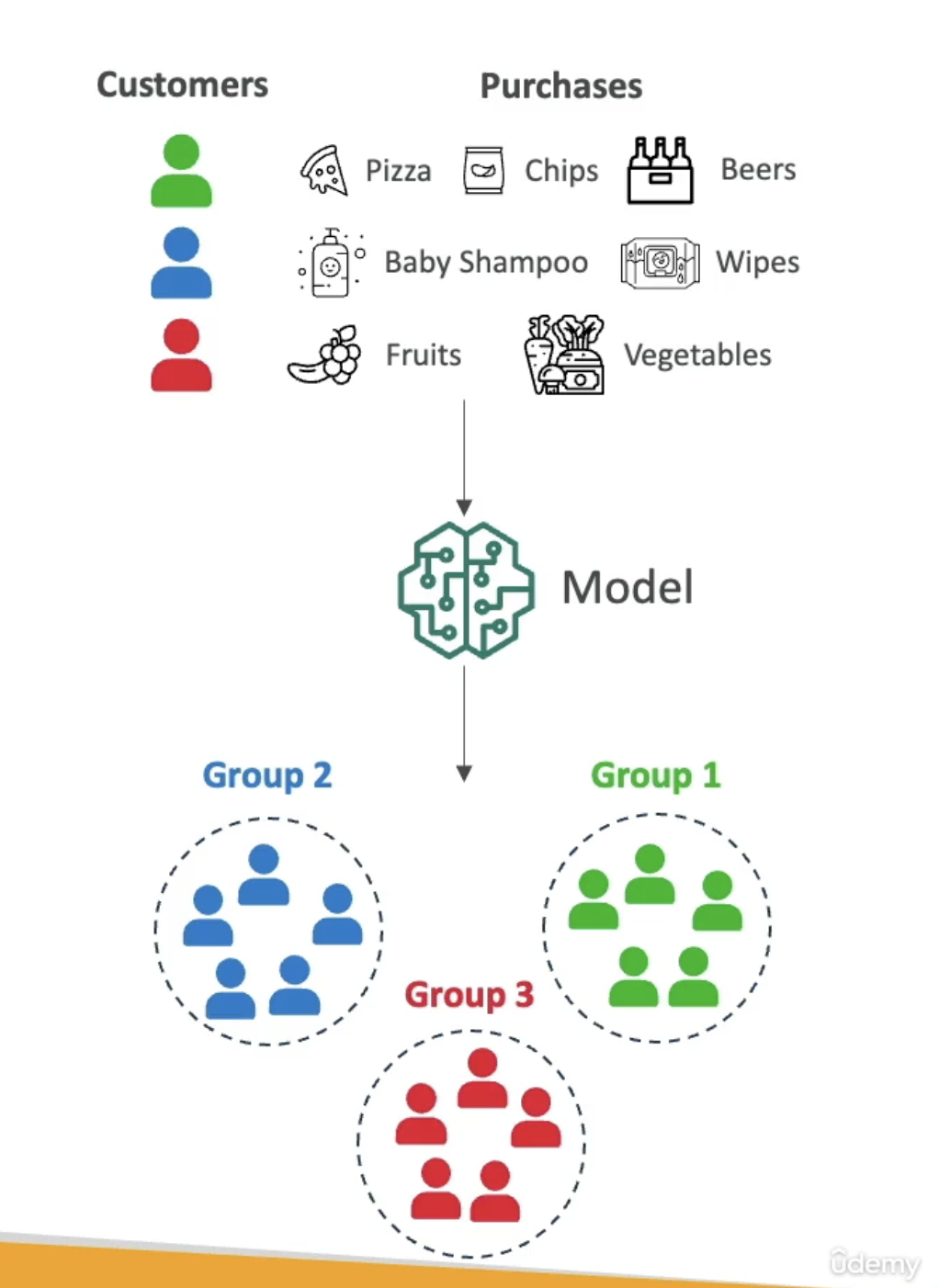
Example — Customer Segmentation
Scenario: An e-commerce company wants to understand the different purchasing behaviors of its customers.
Data: Customer purchase history — purchase frequency, average order value, product categories.
Technique: K-Means Clustering
| Cluster | Purchase Pattern | Likely Interpretation |
|---|---|---|
| Group 1 | Pizza, Chips, Beers | Students |
| Group 2 | Baby Shampoo, Wipes | New parents |
| Group 3 | Fruits, Vegetables | Vegetarians |
The model plots all customers and identifies three distinct groups. The model does not know these are “students” or “new parents” — that interpretation comes from humans.
Outcome: The company can now target each segment with tailored marketing strategies — different email campaigns, promotions, or product recommendations per group.
Key Aspects
- The number of clusters (K) is usually defined by the human upfront in K-Means
- Feature Engineering improves clustering quality — more meaningful features lead to more meaningful groups
- Output always requires human interpretation to assign meaning to each cluster
Use Cases
- Customer segmentation
- Targeted marketing campaigns
- Recommendation systems
- Document or topic grouping
AWS Service
Amazon SageMaker includes a built-in K-Means algorithm for clustering tasks.
Related Concepts
- Unsupervised Learning
- Supervised Learning
- Machine Learning (ML)
- Feature Engineering
- Amazon SageMaker Overview
Exam Domain (AIF-C01)
Domain 1 — Fundamentals of AI and ML
- Task Statement 1.1: Basic AI/ML concepts — clustering is one of the core unsupervised learning techniques.
Links
References